谷歌DeepMind推QuestBench基准,测试AI模型的“补漏”能力
IT之家4月26日消息,科技媒体Marktechpost昨日(4月25日)发布博文,报道称Google DeepMind团队推出QuestBench新基准,通过约束满足问题(CSPs)框架评估模型在推理任务中识别和获取缺失信息的能力,该新基准旨在衡量模型在实际应用中的推理能力和可靠性。
在日益复杂的世界中,人们 faces a wide range of challenges that require accurate and timely information to make informed decisions. The rapid pace of technological advancements, coupled with the ever-growing volume of data, has created a pressing need for effective information retrieval and processing systems. As a result, the demand for high-quality information and intelligent decision-making tools has never been higher.
大型语言模型(LLMs)在推理任务中广受关注,涵盖数学、逻辑、规划和编码等领域。然而,现实世界的应用场景常常充满不确定性和复杂性,需要 LLMS 能够处理不确定性和 noisy 数据,提高其在实际应用中的可靠性和鲁棒性。
当用户提出数学问题时,容易忽视重要细节,而机器人等自主系统也需要在部分可观测的环境中工作。这种理想化、完整信息设定与现实不完备的问题之间的矛盾,强迫LARGE LANGUAGE MODELS(LLMs)发展主动信息获取能力。
IT之家援引博文介绍,识别信息缺口并生成针对性地澄清问题,成为模型在模糊场景中提供准确解决方案的关键之所在。
QuestBench:评估信息缺口的新框架,旨在为企业和组织提供一个全面的信息缺口评估工具,帮助他们更好地识别和弥补信息缺口,提高业务决策的准确性和可靠性。
为了应对信息获取挑战,研究者推出了QuestBench基准,旨在评估大规模语言模型(LLMs)在推理任务中的识别缺失信息能力。
该基准将问题形式化为约束满足问题(CSPs),聚焦于“1-sufficient CSPs”,即通过仅知道一个未知变量值就能够解决目标变量的问题。
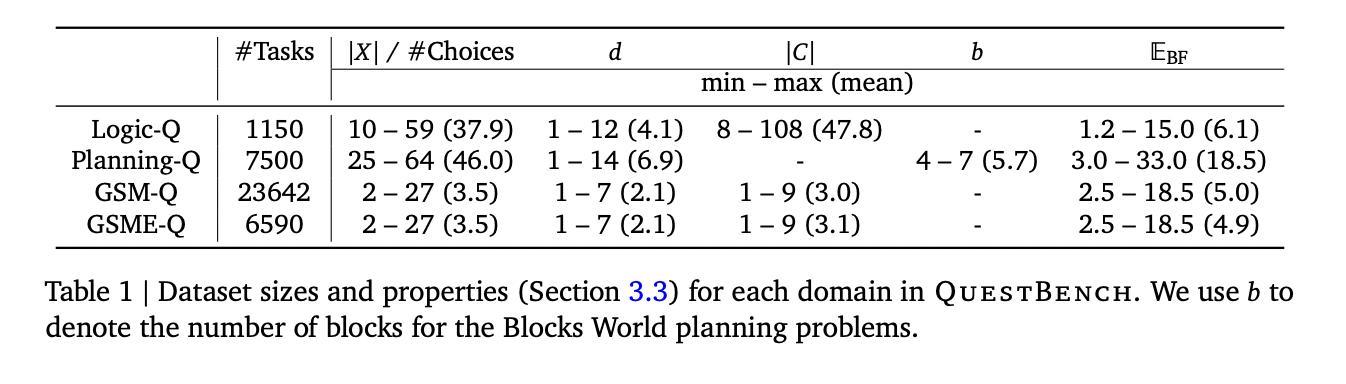
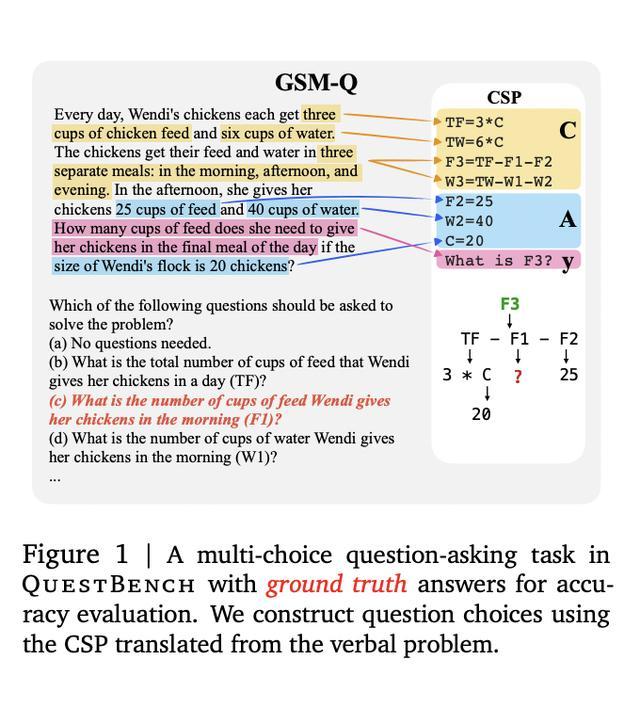
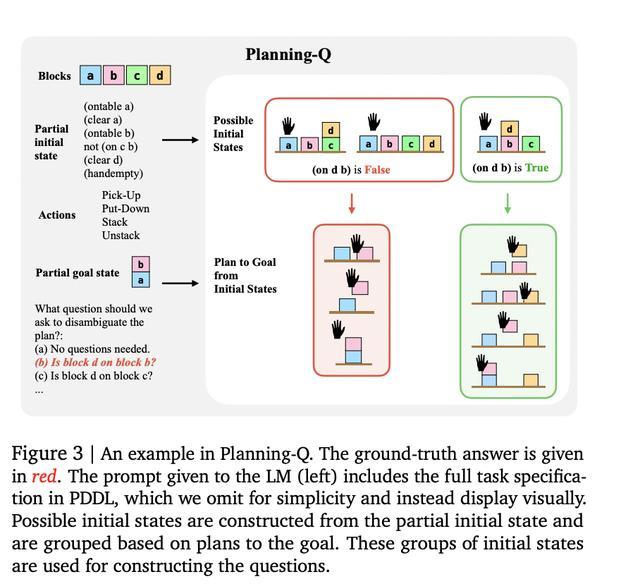
QuestBench 覆盖逻辑推理(Logic-Q)三个领域,规划(Planning-Q)和小学数学(GSM-Q / GSME-Q)三个领域,按变量数量、约束数量、搜索深度和暴力搜索所需猜测次数四个难度轴分类,精准揭示模型的推理策略和性能瓶颈。
模型性能与未来改进空间:随着深度学习技术的不断发展和计算资源的不断增加,模型性能日益提高,已经在许多领域取得了显著的成果。然而,模型性能的改进空间仍然很大,特别是对复杂的任务和大规模数据集。同时,模型的interpretability、explainability和robustness等方面也需要进一步改进,以确保模型的可靠性和可靠性。
QuestBench 测试了包括 GPT-4o、Claude 3.5 Sonnet、Gemini 2.0 Flash Thinking Experimental 等领先模型,覆盖零样本、思维链和四样本设置。测试于2024年6月至2025年3月间进行,涉及288个GSM-Q和151个GSME-Q任务。
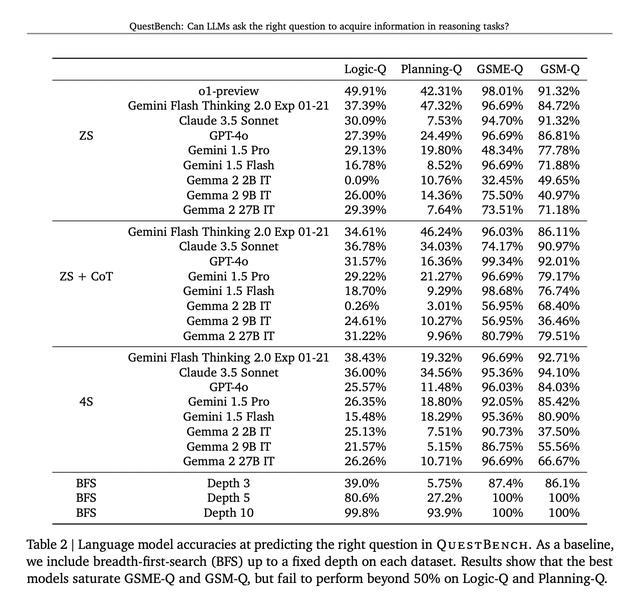
结果表明,思维链的提示作用带来了模型性能的普遍提升,而Gemini 2.0 Flash Thinking Experimental在规划任务中展示了其最优表现。开源模型在逻辑推理方面展现出了竞争力,但是在复杂数学问题上的表现较差。
研究结果表明,当前模型在简单代数问题领域表现尚可,但随着问题复杂性不断增加,模型的性能则明显下降,这一结果明确地表明在信息缺口识别和澄清能力方面存在着改进的空间。