不学Sora?这家国产AI搞了个“无限续杯”的视频模型

这回,世超掏着一个据说不一样的视频模型:sand.ai的Magi-1。
具体有啥不一样?我们先翻了翻sand.ai的资料,发现他们团队还真是有点来头。
创始人曹越和联创张拯早在2021年就展开了合作,共同推动万引神文Swin Transformer的发展。他们曾经都是科技界的黄埔军校 —— 微软亚洲研究院的员工。曹越还创办了光年之外。
在强强联手的buff加持下,sand.ai创立仅仅一年多就拥有了自己的第一个视频生成模型Magi-1。
据说Magi-1是现在市面上唯一一款能进行无限时长视频续写的模型,还能精细化控制到每一秒生成的内容。
当前视频生成模型的极限普遍在几十秒以内,像可灵那样一分钟以上的视频非常少见。要生成更长的视频,那是另一个不同的技术问题,另外的价钱也无法解决,这是底层模型的技术限制。
而Magi-1支持无限时长的续写功能,还可以每次同时生成最多16个1秒到10秒的视频。
不仅仅是技术有创新,sand.ai还表示,他们已经在4月21日开源了模型,并同步上线产品示范。
连业界大佬都发文力挺sand.ai,李开复的发帖,这是继DeepSeek之后又一个开源的世界级模型。
美团创始人王慧文也为sand.ai这波开源发声:“只有科技的不断前行,才能挽救人类掉入零和游戏的深渊。”

我们对几个官方案例进行了翻阅,发现确实存在一些有价值的信息。
蓬勃的运动速度,带着激越的能量!

再看看这丝滑的镜头转换!

这一下子让世超有点期待了。
然而,需要先冷静下来。测试结果表明,想法具有很大的潜力,具备优势和特色,但生成的效果仍需要进一步提升。

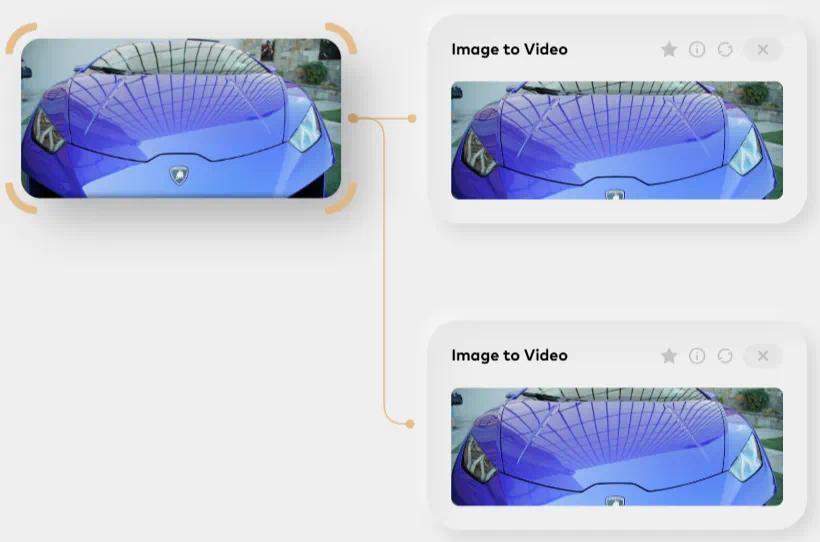
我们先捕捉到梦中情车的正面特写慢镜头,准备续写接下来世超驾驶 Lamborghini 秋名山车神再世的画面。
在测试的过程中,我们发现Magi-1对运动速度和镜头的控制确实非常出色。兰博基尼在路上的疾驰效果被完美地呈现出来,镜头也富有电影般的感官体验,始终聚焦于跑车的精彩表现。
Magi-1还有一个很明显的优点,即对视频主要物体的保护达到极高的标准。它不会出现在多次续写后,物体形状发生剧烈变化的情况,如跑车变身大黄蜂等。
它对物理环境的理解也非常正确,车辆始终保持在地面上,没有出现任何低空飞行或其他不寻常的操作。

然而,Magi-1似乎有些健忘。比如前三段生成的视频都清楚地表明车后是一面墙,结果第四段却直接展现了一个倒车摆尾,丝滑地上路了。
然而,场景理解自从上路就越来越抽象了。除了克苏鲁风绿化带,提示词让它在红灯前刹车,遵循交通规则的本意,它却直接来个交通肇事。
虽然确实是在红灯前刹车,没毛病。

然而,我们接下来的测试发现,效果不佳,也不能完全归咎于模型,因为可能是提示词出了问题。
Magi-1的提示词增强机制可以将简单的提示词扩展成更详细、易于模型理解的指令,但是在实际应用中,这个机制却出现了添油加醋、假传圣旨的现象。
让小鸡玩具跳起来,挑战自己给自己加上难度,同时让小鸡扇动翅膀。

但如果我们把提示词复制一遍,只删掉扇翅膀的要求,关掉提示词,使我们能够快速地把握主要信息,视频效果立刻好起来了。
左图有扇翅膀提示词,右图去掉扇翅膀提示词。

请提供要修改的段落内容,我将对其进行语言润色,提升表达质量。
效果看起来并不错,环境没有崩溃,小鸡也没有崩溃,镜头确实移动了。

所以这里有个小小的功能改进建议嗷:
在进入视频生成环节之前,最好让大家伙儿关注增强的提示词是否准确,为大家提供一个修改提示词的机会。
毕竟生成一次还是需要等待挺久的,要是最后才发现中间提示词被魔改了,有点搞心态。
这也侧面反映了 Magi-1 对于提示词的非常敏感和高要求。想要使用好它,需要了解什么样的提示词才能让它发挥出最佳的效果。

看完测试,你可能觉得,这个模型有点拉呀,现在生成效果比这个好的多的是,为啥把它拿出来说?要知道,这个模型并不是最新的版本,我们的团队一直在努力地改进和优化,它的性能和效果会随着时间的推移而不断提高。
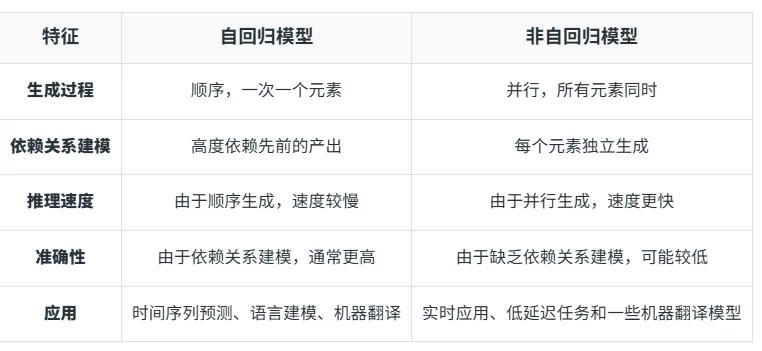
由于它与我们熟悉的 Sora 等非自回归 DiT 模型(Diffusion Transformer)的技术路线完全不同,是一个自回归生成模型(Autoregressive model),具有独特的架构和生成机理。
作为一次创新尝试,它展现出独特的优势和潜力。

AR 模型就像一条环环相扣的锁链,每一次生成视频的新一帧,都在前一帧的基础上建立起紧密的联系。这样生成的视频相邻帧之间就会具有强烈的相关性和连续性。
而 DiT 模型更像是一条伪装成锁链的铁环链条,它为了提高效率,会同时生成大量帧;然而,它却无法兼顾帧与帧之间的关联和逻辑关系。
为什么sand.ai要尝试一条新路,选择和主流视频生成都不一样的 AR 模型呢?正是因为它们认为,当前市场中的 AR 模型大多数都是基于传统计算机视觉和深度学习的技术,并且这些技术都存在一定的局限性和挑战。例如,传统计算机视觉技术通常需要大量的人工标注数据,而深度学习技术则需要大量的计算资源和数据存储空间。因此,sand.ai认为,需要一种新的 AR 模型,它可以更好地适应复杂的实际应用场景,并且可以更好地融合人工智能和计算机视觉技术。
我们对sand.ai团队进行了简短的采访,获得了对Magi-1的专业和长远解释。
sand.ai声称,他们早已洞察到了AR模型在视频生成领域的潜力,远在Sora发布前。他们坚持AR的开发,因为它在大语言模型上已经被证实是可扩展的(scalable),这种可扩展性在很大程度上决定了这个技术在未来的发展上限。
理论上,AR 模型和语言模型的技术路线更趋近,有可能让语言和视频统一建模,使文字和视频之间的关系就像现在文生图一样紧密,效果有可能实现一次跃迁。
另一方面,视频随着时间的推移往往显示出物理和逻辑的深入相关性。例如,篮球如果被篮筐拦住,它便会终止掉落的过程。
下图是用Magi-1生成的。

DiT每帧独立生成的方式可能会中断这种关联,导致篮球直接穿透篮筐。而AR则更好地理解视频内容,不仅内容合理,还在运动幅度和速度上表现出更加逼真的效果。
虽然技术路线目前还没有完全成熟,但sand.ai 相信 AR 将是未来。随着技术的不断迭代,也许将会找到最合理的 AR 模型视频生成的方式。
因此,按照他们的说法,在对技术进行全面而理性地分析后,sand.ai 对 AR 视频生成进行了深入的探索。

在视频生成领域的火爆浪潮中,sand.ai的出现似乎晚了些,但是在AR视频生成的更高维度上,他们却率先而至。
最重要的是,sand.ai这波开源,属实格局拉满。
科技行业的每一次重大开源都会带来一场百花齐放的景象。期待sand.ai未来的更多产品,以及更多团队在Magi-1基础上激发的创新成果。
