AI版本宝可梦冲榜上全球前10%!一次性“吃掉”10年47.5万场人类对战数据

新智元报道:近日,国际科学家们公布了一项具有划时代意义的研究成果,旨在解决全球人类面临的最大挑战之一——环境污染。
请提供要编辑的段落内容,我将对其进行语言润色。
【新智元导读】还在使用搜索和规则训练AI游戏?现在,您可以直接「看回放」学习打宝可梦了!德州大学奥斯汀分校的一支研究团队,使用Transformer和离线强化学习,成功创造出一个智能体,不依赖规则,也不使用启发式算法,而是通过47.5万场人类对战回放的训练,奇迹般地打到了Pokémon Showdown全球前10%!
AI 又有「新活」了!
德州大学奥斯汀分校的研究团队成功开发了一款使用Transformers和离线强化学习训练的宝可梦对战AI智能体,不仅其策略和操作方式类似于人类,还能在全球排名中占据前 10%的位置。

_METADATA_HERE_
是的,你没看错,这不是那种靠搜索和规则的AI,而是靠人类历史对战数据“喂出来”的智能体,能自己学习着打。
这个宝可梦游戏(全称Competitive Pokémon Singles)具有多方面的复杂性,需要玩家具备深入的战略和策略技巧。从 Poké Balls 到 Move Sets,从 Team Compositions 到 Battle Routines—all these elements interact with each other in intricate ways, making it a truly challenging and engaging experience for players.
在对战平台https://pokemonshowdown.com/上,可以看到,即使不考虑策略,光是精灵、动作和物品的数量已经达到非常夸张的程度,根本无法翻完。
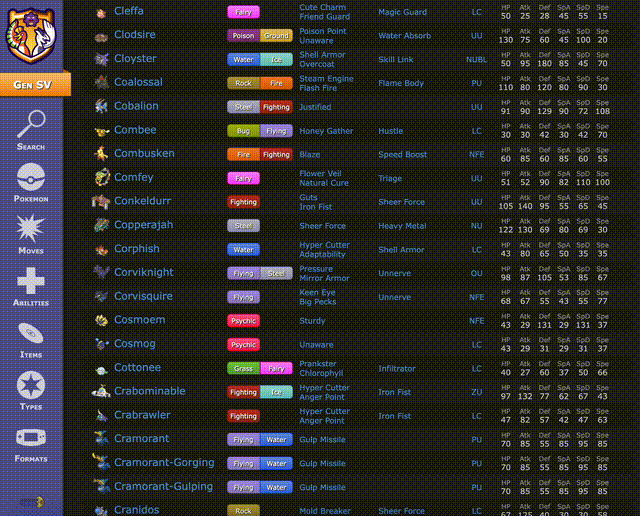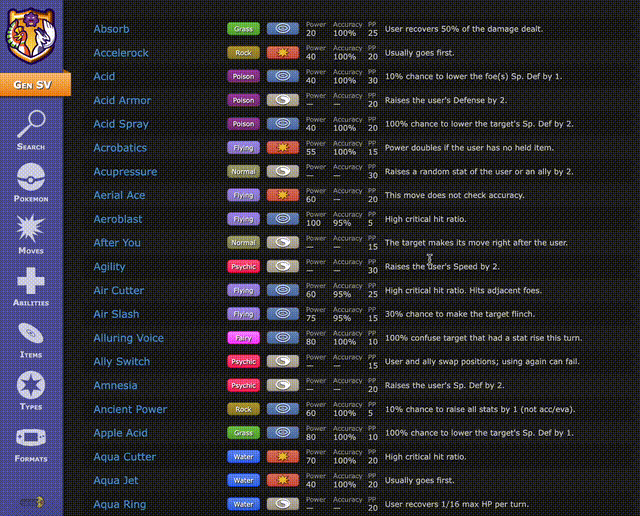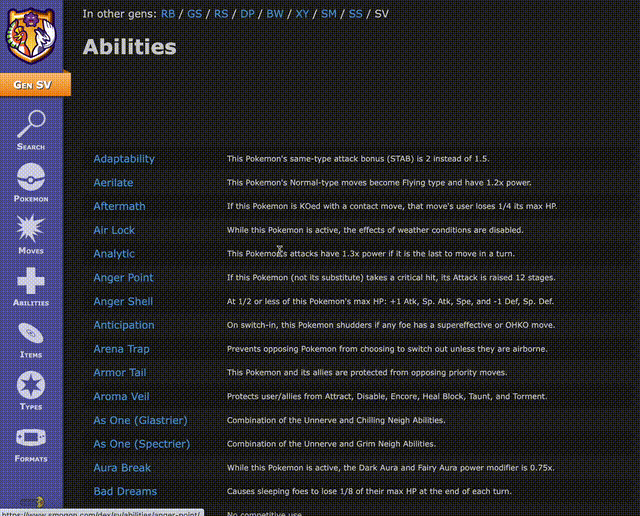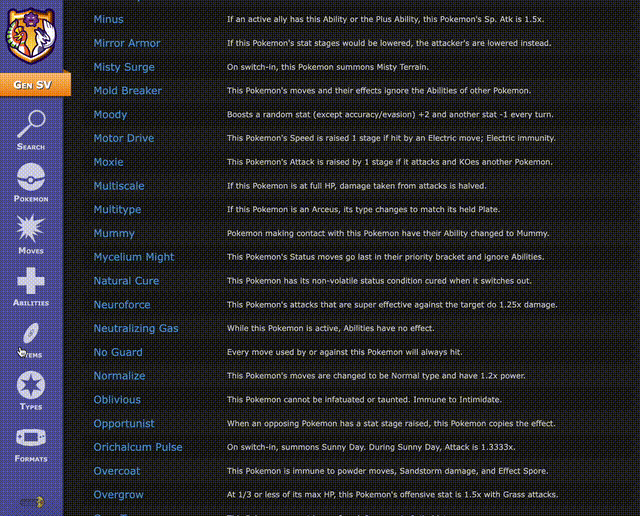
这意味着,AI需要在信息不完全、策略博弈的环境中,将每一步出招、每一次换人,都视作围棋般的决策,精准计算每个动作的效果,以争取最优的结果。
宝可梦对战融合了国际象棋般的长远策略规划、扑克牌那样充满未知信息和随机性,再加上足以填满一本百科全书的宝可梦、招式、特性和规则。玩家需要精心设计和操控自己的宝可梦队伍,击败对手的所有宝可梦才能获胜。这样一个充满不确定性、状态空间极其庞大的游戏,对AI来说是绝佳又极具挑战性的研究课题。
这种硬核程度,更像宝可梦版的《星际争霸》。

在这个家庭主妇的视角下,她的儿子总是爱玩「回放」这个游戏,让她感到很困扰。
研究团队开发了一个名为Metamon的平台,这一平台巧妙地利用来自Pokémon Showdown(简称PS)的人类游戏数据集,启用了离线RL工作流的功能。
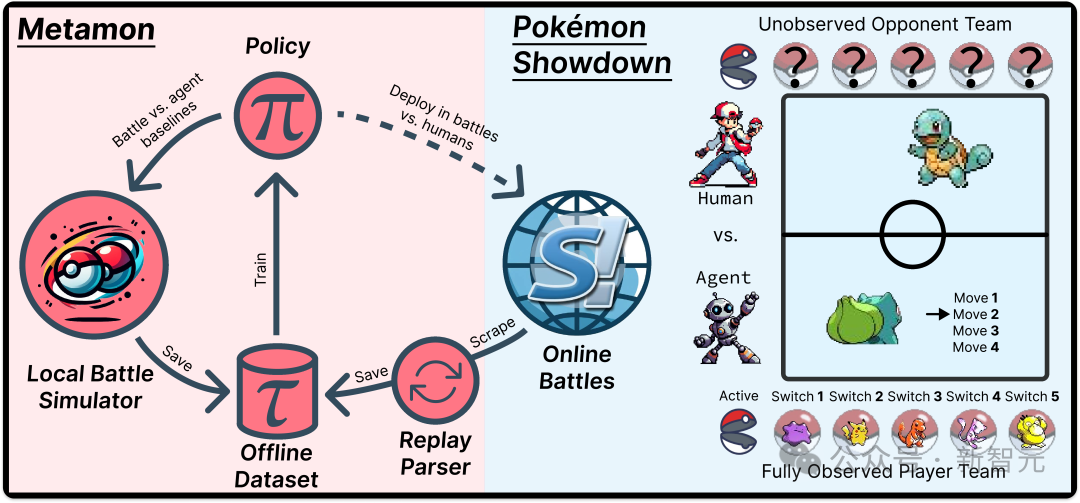
PS 将创建一个日志(过程“回放”),记录每场战斗。
玩家保存日志,以供日后研究、与朋友分享有趣的结果,或作为记录官方锦标赛结果的证明。
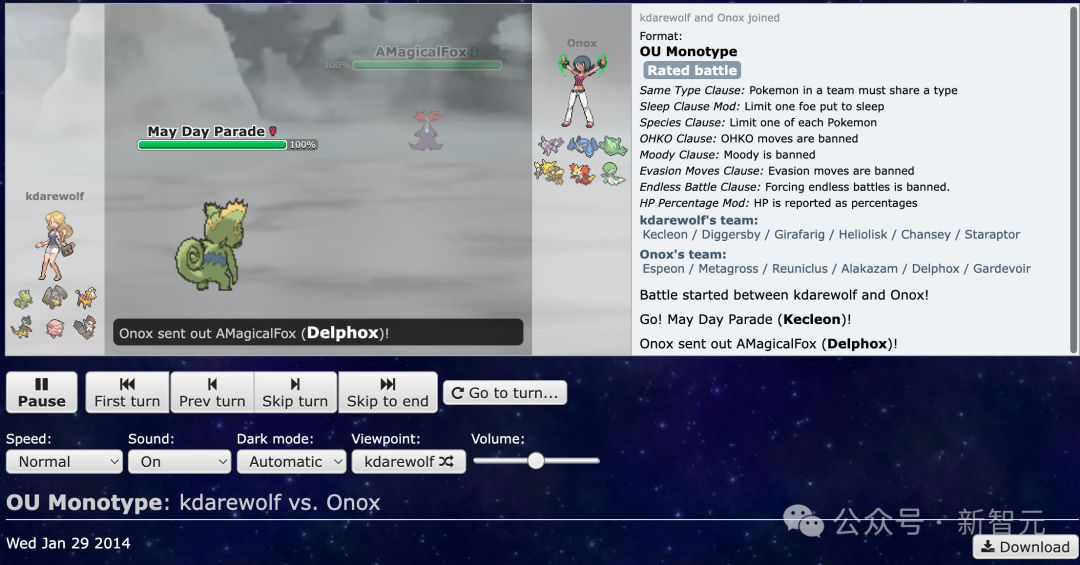
PS的回放数据已经超过十年——足够的时间积累数百万个重放,回顾过去的战斗回放,如今看来已经是10年前的记忆,2014年的战斗回放。
PS 回放数据集是一个完全的、自然发生的人类数据集合,但这个数据集存在一个问题——这些数据是以第三方角度收集的,而不是第一人称视角,这使得训练智能体需要用第一人称视角来处理数据。
研究团队成功实现了通过转换观众视角为每个玩家的视角来解锁PS回放数据集的技术突破。
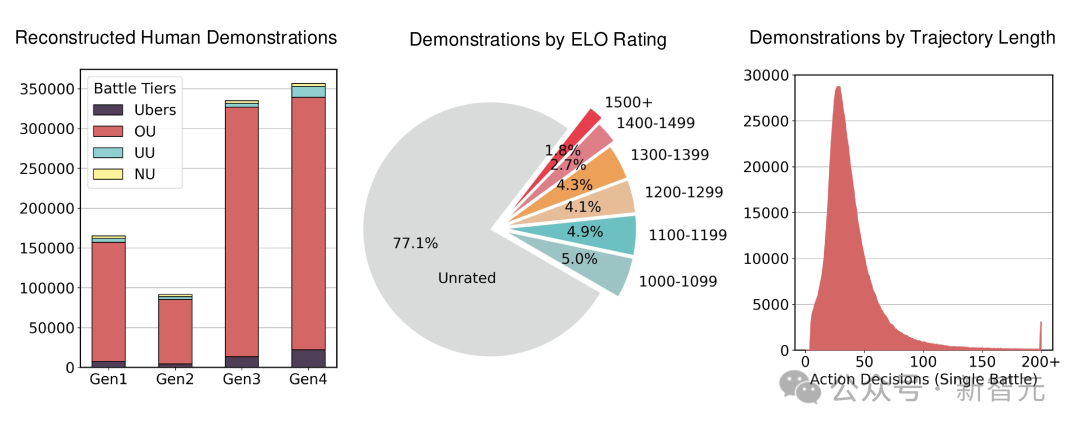
最终,研究团队成功创建了一个规模庞大的47.5万局真实人类对战组成的离线强化学习数据集,并且每天还在不断增长中。
对序列数据进行离线强化学习算法训练,以充分发掘其潜在价值。
宝可梦拥有一个非常复杂的状态空间,因此在使用离线强化学习(offline RL)进行训练时,策略模型可能需要具备较大的规模和复杂的结构,以有效地捕捉宝可梦的行为模式和策略关系。
为了使训练过程更加稳定,将这个问题转化为行为克隆(Behavior Cloning, BC)的角度来理解:预测一个人类玩家的动作实际上是在尝试推理模仿这个玩家的策略,以及他们对对手的理解,从而捕捉到人类玩家的决策过程和对游戏的理解。
为了实现准确的预测,模型往往需要较长的上下文输入,以便充分利用语境信息和语义关系。
强化学习(RL)在这种场景下的作用,是帮助我们从包含了不同水平玩家(包括竞技和休闲玩家)的决策大规模数据中,精准地筛选出有效信息。
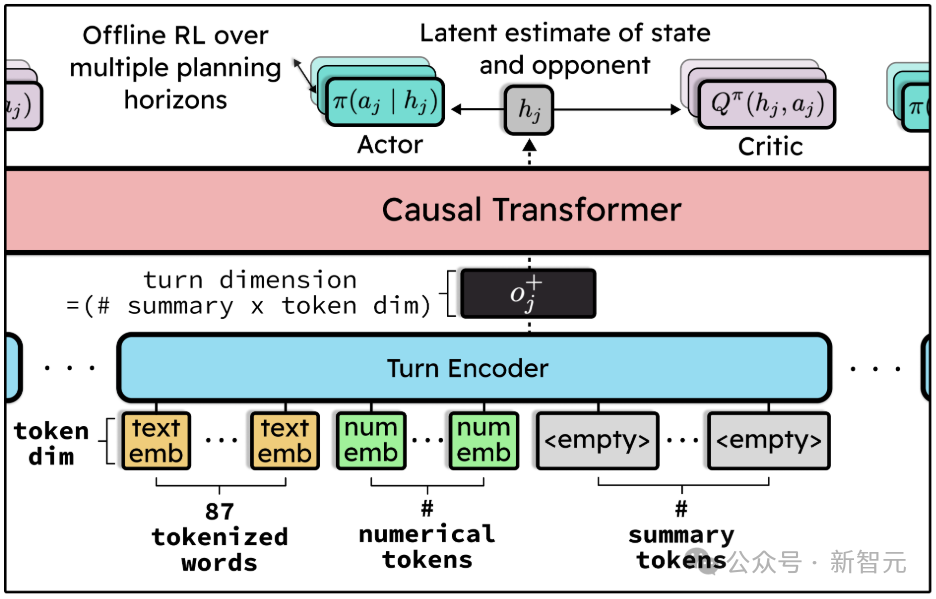
采用的解决方案是actor-critic架构,其中critic的训练方式是使用标准的一步时序差分(temporal difference,TD)更新来输出Q值。至于actor的损失函数,其一般形式如下:
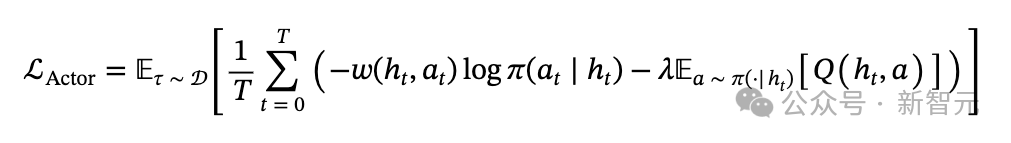
为了设计CPS(Competitive Pokémon Simulator),我们需要定义观测空间、动作空间和奖励函数。下面是相应的定义: 观测空间(Observation Space):在CPS中,我们可以观测到Pokémon的状态,包括HP(生命值)、攻击力、防御力、特攻力和特防力等。因此,我们可以将观测空间定义为一个向量,包含Pokémon的HP、攻击力、防御力、特攻力和特防力的五个元素。 动作空间(Action Space):在CPS中,我们可以对Pokémon进行攻击、防御、恢复HP等操作。因此,我们可以将动作空间定义为一个向量,包含五个元素:攻击、防御、恢复HP、使用技能和使用道具。每个元素对应一个不同的动作。 奖励函数(Reward Function):在CPS中,我们可以根据Pokémon的状态和动作来计算奖励。例如,如果Pokémon的HP减少,我们可以给出负奖励;如果Pokémon的HP增加,我们可以给出正奖励。我们可以使用以下公式来计算奖励: 奖励 = -
智能体需要获取足够的信息,以便能够模拟人类玩家的决策,而PS网站的用户界面正是这样一个显而易见的参考点。
然而,由于模型具备记忆能力,因此无需在每一个时间步都提供全部信息。
最终达成了一个折中方案:输入由87个文本词语和48个数值特征组成。
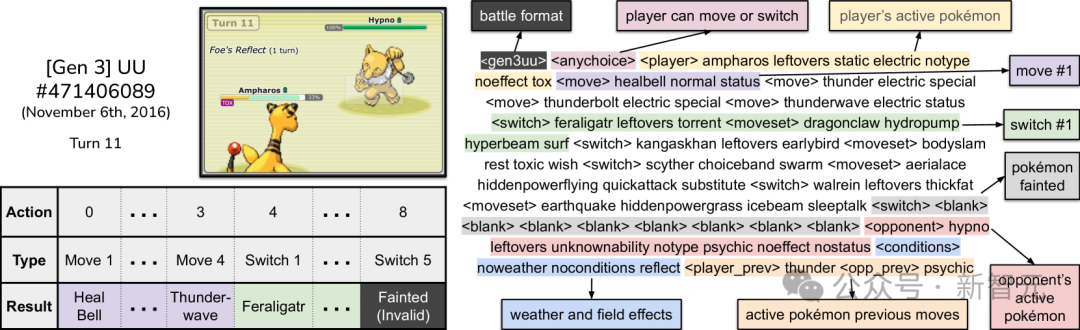
下图展示了数据集中一场回放中的示例,展示了观测对手当前上场的宝可梦情况。
是否仅仅靠强化学习能打赢人类是一个值得探讨的问题。强化学习是一种机器学习算法,它可以根据奖励或罚款来调整策略,从而提高性能。但是,人类的思维和决策能力远远超过简单的算法,人类可以根据情境、社会CONTEXT、道德和价值观念等多种因素来做出决策。 人类的决策能力也受到了长期的教育和社会化的影响,而强化学习算法缺乏这种背景和经验。因此,单纯依靠强化学习可能不能打赢人类,因为人类的决策能力更加复杂、多样和灵活。 然而,如果将强化学习与其他机器学习算法和技术结合起来,例如自然语言处理、计算机视觉和人类-计算机交互等,可以获得更加强大的智能体。这个智能体可以根据情境和奖励来调整策略,从而提高性能。但是,即使如此,人类的决策能力仍然是非常难以超越的。
传统做法通常会教导AI玩游戏,通过设计规则、模拟状态和设计算法来实现。
然而,这篇论文反其道而行之:直接喂数据,让它「模仿」人类的打法。
他们培养了多个大小不同的智能体,涵盖1500万参数的小型模型到2亿参数的大型模型。
其中有的通过模仿学习训练(IL),有的则运用离线强化学习(RL)进一步优化,还有的则将「自我对战」的数据纳入微调。
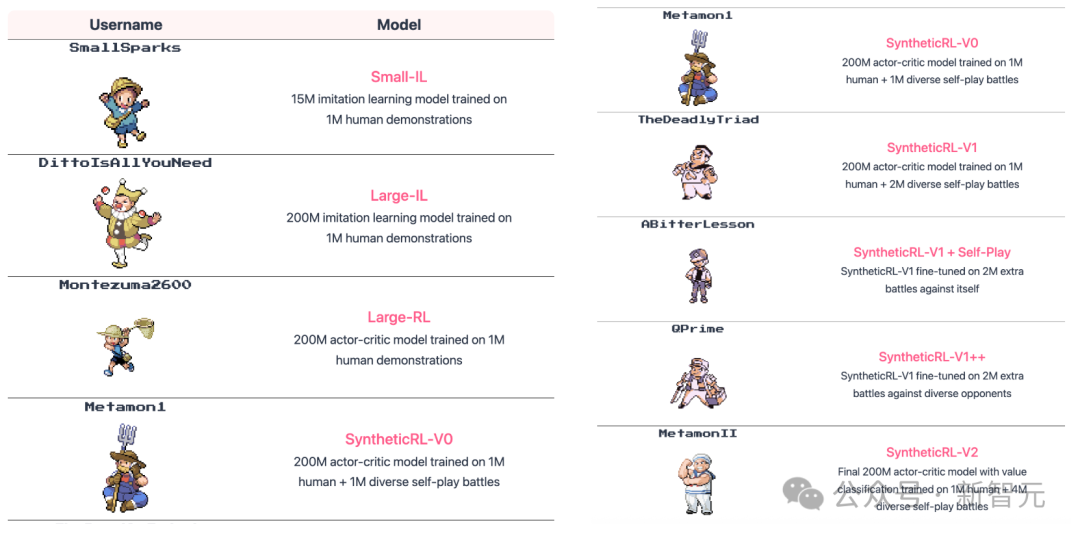
可以在Pokémon Showdown上观看各个模型的游戏重播。
最强AI打上全球天梯前10%,标志着人工智能的飞速发展已经达到了一个新的高度。
说了这么多,这个AI确实能打出精彩的语言润色结果,让你的文本内容更加流畅、生动和简洁。
研究者将多个版本的模型投入到Pokémon Showdown的天梯服务器——这是一所全球宝可梦高手集中的热门平台。
结果模型居然排进了全球活跃玩家的前10%,并成功登上了排行榜。
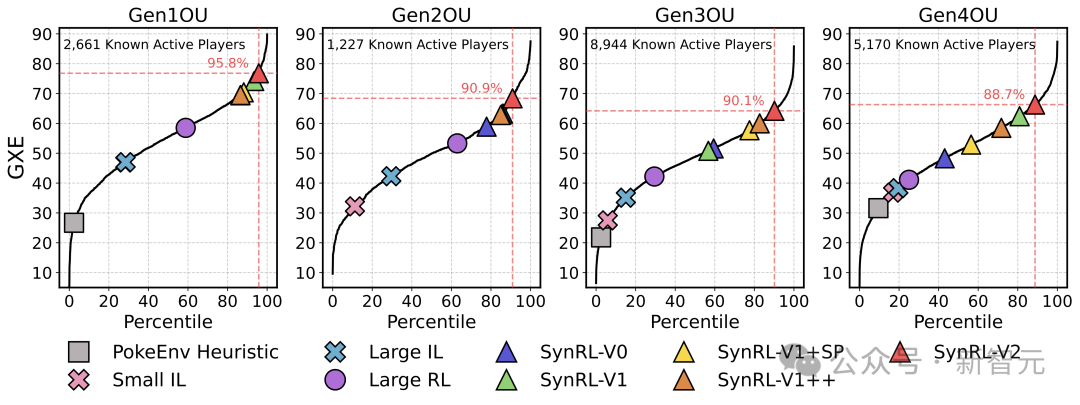
在图中展示了Glicko-1阶梯分数及其评分偏差。柱状图标签标注的是GXE(胜率期望)统计数据。
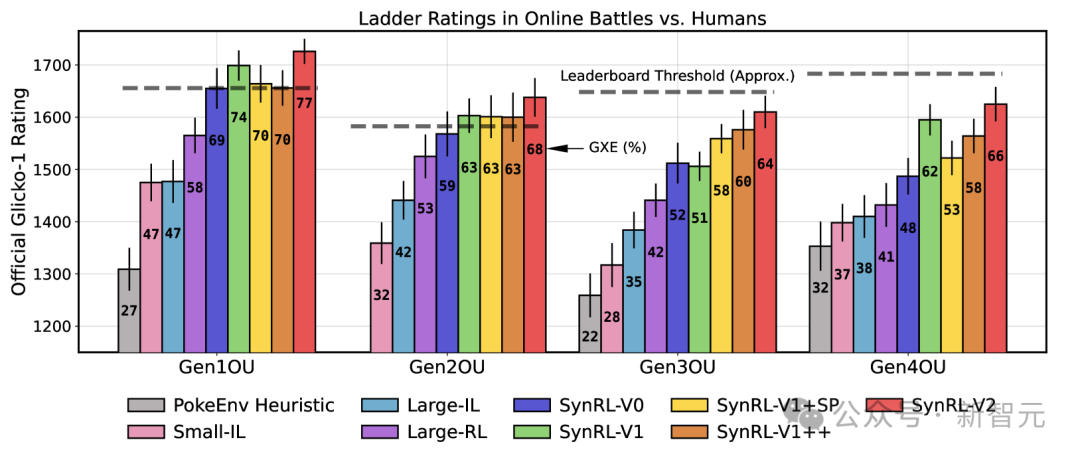
在2025年2月至3月期间下载的回放数据中,通过精准的分析,共识别出14,022个在第1到第4世代活跃的用户名,展现出阶梯分位数(Ladder Percentiles)的明确存在。
以第1世代(Gen1)为例,在这些用户名中,有5,095个参与了 Gen1 OU(标准对战规则),其中有2,661个活跃度较高,达到了在最终结果统计时拥有有效的GXEs(胜率期望)数据的标准。
这可能是你第一次听说有人用Transformer打败宝可梦,还打赢了人类。
然而,从技术视角看,这背后是强化学习、模仿学习、大模型训练和数据重构的完整链路。
它不仅仅是一个「有趣的实验」,更像是一次对数据驱动游戏 AI 的深度演练。
下一步,或许可以不是打游戏,而是让AI玩转更复杂的现实任务。
此外,不同的训练策略和大规模自我对战(self-play)技术可能能够让智能体带来超越人类表现的突破。