DeepSeek-R1“内心世界”首次曝光!AI显微镜破解R1大脑,发现神秘推理机制

新智元报道:随着人工智能技术的不断发展和应用,人们对其可能带来的影响和变化的关注日益加强。
犀牛定慧
【新智元导读】推理模型与普通大语言模型存在本质不同,它们的行为也会因其内在机理而「胡言乱语」甚至「故意撒谎」。Goodfire最新发布的开源稀疏自编码器(SAEs),基于DeepSeek-R1模型,为我们提供了一把「AI显微镜」,窥探推理模型的内心世界。
推理模型的内心世界是由复杂的算法和数学公式组成的,它们通过对输入数据的分析和处理,生成预测结果或解释。推理模型可以被视为一种能够模拟人类推理过程的机器,它们能够从数据中学习,自动地发现 Patterns 和关系,并且能够将这些信息应用于新的未知数据中。 与普通LLM(Large Language Model)不同,推理模型具有一些本质的区别。LLM主要用于自然语言处理和语言生成,它们通过训练大量的语言数据,学习到语言模式和结构,从而生成文本或对话。LLM的主要目标是生成高质量的语言内容,而不是进行推理或解释。 推理模型则不同,它们的主要目标是通过分析和处理数据,生成预测结果或解释。推理模型可以用于各种领域,例如计算机视觉、自然语言处理、生物信息学等。它们能够从数据中学习,自动地发现 Patterns 和关系,并且能够将这些信息应用于新的未知数据中。 总的来说,推理模型和LLM都是机器学习算法,但是
一直以来,AI内部的运作机理就像一个「黑箱子」,其复杂的算法和数据流程让人难以捉摸。
我们知道模型输入的是什么,也能看到它们输出的结果,但中间的黑箱过程,就连开发AI的人自己也不知道。
像谜一样,暗藏着秘密,等待被解开的瞬间。

这种不透明的机器学习算法带来了很多问题。比如,我们不知道模型为什么会「胡说八道」,也就是出现所谓的「幻觉」,这导致了对模型的不确定性和不信任。
更可怕的是,有些情况下模型还可能会撒谎,甚至是故意骗人!
这给AI的安全应用带来了很大的阻碍。
一直有团队试图破解这个「黑箱子」。比如不久前,Anthropic就推出了一项研究,深入Claude 3.5 Haiku的「脑子」,揭开了一些它运行的秘密。
就在刚刚,AI安全公司Goodfire发布了首个基于DeepSeek-R1训练的开源稀疏自编码器(SAE),为我们提供了理解和引导模型思考的新工具。

SAE(Standard Automotive Electrical)是一种国际标准,用于描述汽车电气系统的接口、连接器、引脚、电压、电流等参数。SAE标准为汽车制造商和零部件供应商提供了一个共同的语言和标准,用于描述和设计汽车电气系统,使得不同厂商之间的互操作性和可替换性更好。
稀疏自编码器(SAE)是一种独特的神经网络结构,具有「压缩包」的相似性,能够将复杂的数据压缩成更加简洁的形式,然后再恢复原始数据,实现高效的数据表示和存储。
不同之处在于,SAE会确保中间处理层(隐藏层)中只有少数神经元被激活,大部分神经元保持「沉默」,即在激活状态接近零。
这种「稀疏性」就像团队合作:假设你有一个团队,每次任务只需要少数几个人完成,SAE通过让大部分神经元「休息」,只让少数神经元「工作」,从而学习数据的关键特征。
这不仅使模型的效率和可读性大大提高,还能让结果变得更易于理解和分析,以至于减少数据维度,同时保留和强调最重要的信息。
SAE就像一个挑剔的专家,它只保留数据中最有价值的部分,特别适用于需要高可解释性的场景,能够为决策提供坚实的依据。
像DeepSeek-R1、o3和Claude 3.7这样的推理模型可以通过增加「思考」计算量,为复杂问题提供更加可靠、更加连贯的响应。
然而,理解它们的内部机制仍然是一个挑战。
然而,Goodfire这个基于DeepSeek-R1训练的SAE,则可以像显微镜一样,深入模型内部,揭示R1是如何处理和响应信息的。
研究者从SAE中发现了一些有趣的早期洞察,通俗点说就是:这些早期洞察不仅反映了当时的科学认识和技术水平,也预示着未来科技的发展方向。
想要有效“引导”模型,得等到它生成完“好的,用户问了个关于……”这样的语句,而不是直接用类似“think”这样的明确标签。这说明模型内部的推理token方式挺出人意料的。
如果"引导"过头,模型反而可能退回到原本的行为,感觉它内部好像有种更深的"自我反省"和"自我调整"。
这些发现表明,推理模型和普通的大语言模型在根本上具有深远的差异。

Goodfire感受到对加快可解释性和对齐研究方面的进展的激动情绪,目前它们已经将这些SAE开源,旨在确保人工智能系统既安全又强大。
开源地址:https://github.com/goodfire-ai/r1-interpretability
推理模型的内部结构通常由多个组件组成,旨在模拟人类的推理能力。这些组件包括:神经网络、 attention 机制、决策树、逻辑规则等。神经网络能够学习到复杂的模式和关系,attention 机制能够帮助模型关注到相关的信息,决策树能够对决策过程进行可视化和解释逻辑规则能够提供规则化的推理能力。这些组件之间的交互和协作,使得推理模型能够更好地解决复杂的推理问题。
本次研究团队分享了两个最先进的开源稀疏自动编码器(SAE),展示了它们在处理高维数据和高效优化的能力。
研究人员的早期实验表明,R1与非推理语言模型在本质上存在着明显的区别,并且需要一些新的见解来理解和解释这种差异。
由于R1是一个非常庞大的模型,因此对于大多数独立研究者来说,本地运行变得非常困难。因此,团队上传了包含每个特征的最大激活示例的SQL数据库,以便于研究者更方便地访问和使用。
本次分享的SAE已经学习了许多能够重建推理模型核心行为的特性,例如回溯,这些特性将有助于SAE更好地理解和模拟人类的推理思维。
首先展示的是通用推理SAE中的5个精选特性(比如研究团队命名为Feature 15204),分别展现出来:
回溯:当模型在推理过程中识别出错误,并能够明确地纠正自身的特性。下图中的「wait...not」表明模型意识到错误,从而回溯并进行纠正。

自引用指的是模型在响应中引用其先前的陈述或分析时所具备的功能,例如下图中的「earlier」、「previously」等。

在模型引用了子集或子序列后,触发了相应的功能。

用于标识模型需要跟踪的实体,拥有了功能。

在多步骤计算的结果之前:在多步骤计算结果之前触发的功能。比如下图中各个公式计算前触发的「空格」,这些空格将影响最终的计算结果。

推理机制的可解释性是指机器学习模型在推理过程中,对输入数据进行分析和处理的逻辑和机理是否能够被清楚地理解和解释。良好的推理机制需要能够提供明确的解释,帮助用户理解模型的决策过程和结果。
如果想要「解释」推理模型的内部机制,目前有办法。机器学习模型的解释性技术,如LIME(Local Interpretable Model-agnostic Explanations)、SHAP(SHapley Additive exPlanations)等,可以帮助我们理解模型的内部机制。这些技术可以生成解释性结果,展示模型是如何基于特定的输入特征来做出预测的。
研究团队成功创制了一款工具,旨在通过逆向工程神经网络的内部组件,科学地理解它们是如何处理信息的。
关于这一领域的最新研究,例如Anthropic在Claude中进行的电路追踪研究,揭示了从心算到幻觉等模型行为背后的计算路径和特征。
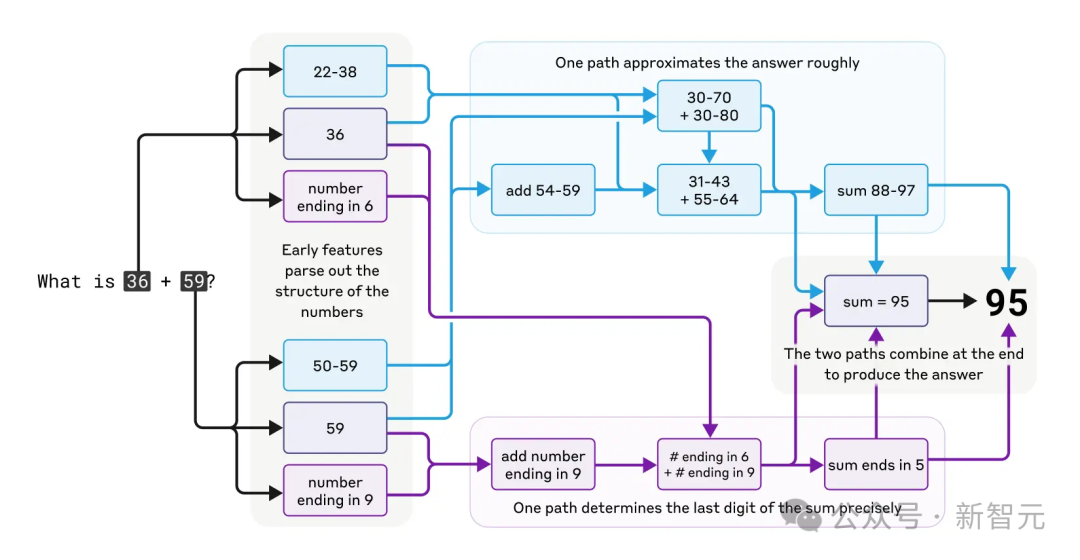
Claude在心算时展现出复杂而平行的思维过程。
发展这种更深层次的理解,对于科学进步和确保这些日益强大的系统可靠且符合人类意图而言,至关重要。
为生成式AI能力的前沿构建可解释性工具是至关重要的。
虽然 SAE 并不能解决推理机制可解释性的全部问题,但它们仍然是当今研究模型推理机制工具箱中的核心“武器”,为我们提供了极其有价值的分析和解释手段。
无监督可解释性技术的进一步发展最终可能允许更可靠地对齐、按需增强或抑制特定推理能力,甚至在不损害整体模型性能的情况下纠正特定故障模式。
如果能实现这一愿景,也许对于人类来说,现在仍然是「黑箱」的深度学习大模型的真实理解将会有了一天。
为DeepSeek-R1开发的SAE,旨在探索深海领域,探测海洋深处的生物资源和地质结构,为 marine 生物学、地球科学和环境保护的研究提供了新的视野和工具。
团队为DeepSeek-R1发布了两个SAE,旨在探索海洋深处的未知领域,推动海洋科学的前沿研究。
在自定义推理数据集上使用R1的激活进行训练,这个数据集已经开源了。
第二个使用了OpenR1-Math,这是一个用于数学推理的大规模数据集。
这些数据集使得能够发现R1在回答那些考验其推理能力的难题时所使用的特征。
在671B参数下,未蒸馏的R1模型在大规模运行时存在着工程挑战。
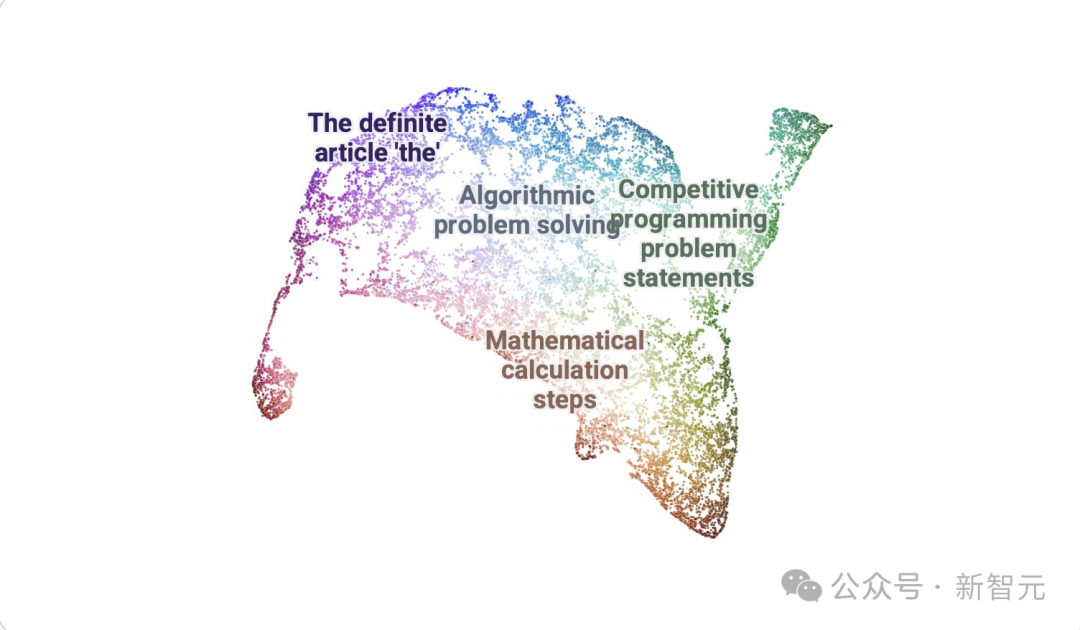
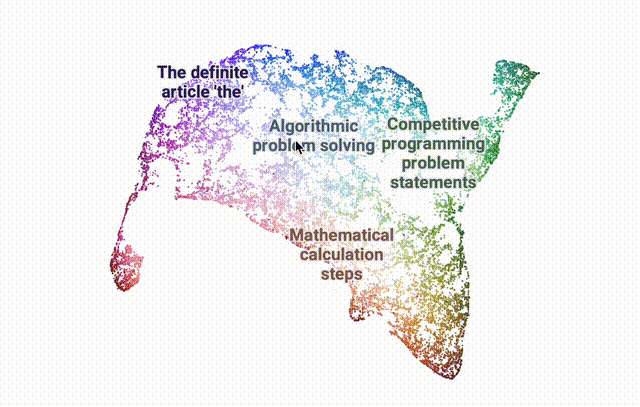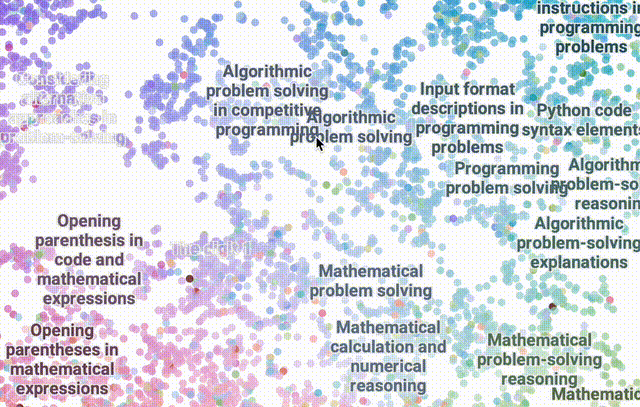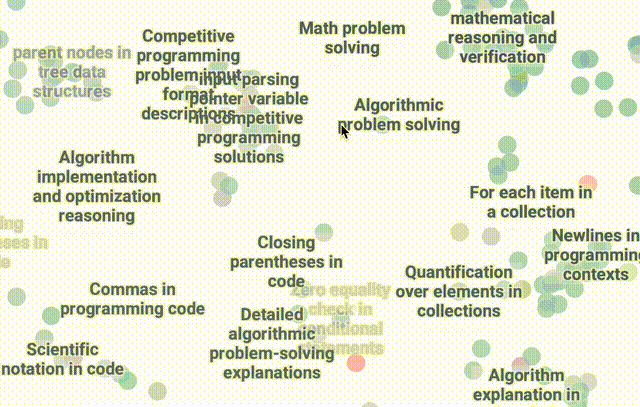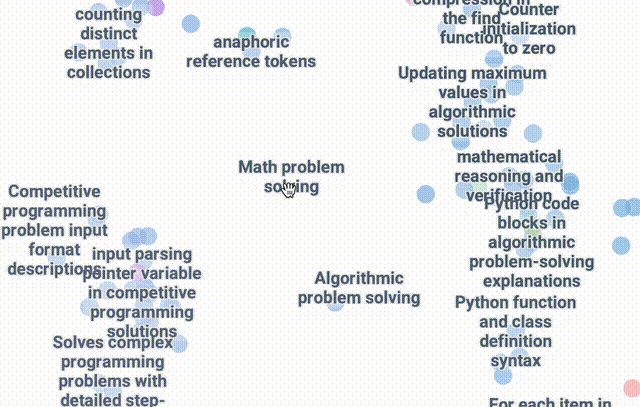
使用DataMapPlot创建了通用推理SAE特征的交互式UMAP可视化的特征图。
UMAP(Uniform Manifold Approximation and Projection for Dimension Reduction)是一种用于降维的算法和工具,基于流形学习和拓扑数据分析的数学理论。
UMAP 将高维度的数据,具有许多特征或变量的复杂数据,映射到低维度空间,通常是 2 维或 3 维空间,以便于可视化和深入分析。
关于引导R1的两个初步见解,分析表明,R1的引导机理可能与传统的电化学引导机理不同,引导R1的两个初步见解可以从以下两个方面入手:首先,R1的引导机理可能是通过非电化学反应实现的,这种机理不同于传统的电化学引导机理;其次,R1的引导机理可能是通过复杂的Chemical-Physical过程实现的,这种机理也不同于传统的电化学引导机理。
虽然还没有系统地研究这些特征的出现频率或原因,但这里想分享两个关于引导R1的见解,这些是在非推理模型中没有遇到过的。
在「好吧,用户问了一个关于……」之后进行引导
通常会从模型响应的第一个token开始进行引导。
然而,直接在R1思考链条的开始阶段进行引导是无效的。相反,需要等到模型以类似"好吧,用户问了一个关于..."这样的话语开始响应之后,才能有效地进行引导。
在这种「响应前缀」的末尾,存在注意力汇聚(attention sinks)的现象,即某些token的平均激活强度远高于正常水平。
通常情况下,注意力汇聚会出现在模型响应的初始阶段。这表明,R1在开始响应之前并没有真正识别出自己已经进入了「真实的响应」阶段,直到「好吧……」这个前缀出现时才开始聚焦。
研究人员最终结点,像上述这样的短语在R1训练时的推理路径中非常常见,因此模型实际上将其视为某种提示的一部分。类似的前缀在R1的推理路径中极为常见,超过95%的英语推理路径都以“好吧”开头。
在提示中出现的特征分布出现了显著的变化,提示了思考轨迹和助手的响应之间的关系。
这种微妙的、不直观的R1内部过程特征表明,最初对外部用户来说直观的概念边界可能并不完全符合模型自身所使用的边界,反映出一个复杂的、多层次的关系网络。
引导示例#1,在数学问题中交换运算符,比如将times变成了divide。

过度引导R1会导致其恢复原来的行为。
在引导模型时,我们通过调整所操控特征的强度,从而控制该特征对下游模型输出的显著性。
例如,如果增加一个表示“狗”的特征的激活强度,那么模型的输出将更加与狗相关。
通过不断增加特征的激活强度,如果过度引导,通常会观察到模型越来越专注于狗,直到其输出变得不连贯。
然而,在对R1进行某些特征的引导时,发现过度引导反而可能会让模型恢复到原始行为中去。
为了更好地提高工作效率和减少思考时间,许多人开始使用各种工具和方法。从简洁的笔记本到复杂的项目管理软件,从快速的搜索引擎到智能的AI助手,人们逐渐发现自己的工作方式和思考模式都在被改变。
研究员首先推测,模型内部的激活状态受到过度干扰时,它将隐性地感知一种困惑或不连贯的状态,从而暂停调整自身。
为什么这种「重新平衡」效应会特别出现在推理模型中?这种「重新平衡」效应是指推理模型在处理不确定性或不协调信息时,自动地进行调整和平衡,以确保推理结果的合理性和可靠性。这种效应特别出现在推理模型中,因为推理模型需要处理大量的不确定性信息,例如未知的变量、不确定的关系和可能的结果等。为了应对这些不确定性,推理模型需要不断地调整和平衡其推理过程,以确保最终的结果是可靠的和合理的。
研究人员认为,这可能与模型的训练方式相关联,训练过程可能激发模型对自身内部状态的更加隐晦的「察觉」。
从经验上看,推理模型在处理难题时,如果某条推理路径行不通,常常会回溯并尝试其他方法,这暗示它们在某种程度上能“感知”到自己何时“迷路”了。
如果这种现象是推理模型的普遍特性,那么试图改变模型行为——比如抑制不诚实的回答——可能需要更复杂的技术,因为模型可能会找到绕过修改的方法,以至于使其变得更加难以控制。
这件事情的重要性体现在于它对我们的日常生活和未来发展产生了深远的影响。首先,这件事情能够帮助我们更好地理解和处理当前的挑战和困难,对于我们来说是非常重要的。同时,这件事情也能够激发我们内心的激情和创造力,推动我们继续前进和进步。
推理机制可解释性通过深入研究模型如何生成回答,可以帮助我们更好地理解模型的决策过程,提高模型的可靠性和可解释性,从而实现更好的模型应用和控制。
更好地了解模型的能力和局限性,意味着需要对模型的性能和不足进行深入的分析和评估。模型的能力可以体现为其可以解决的任务和问题的范围,而局限性则体现为模型在某些特定场景下不能很好地解决的问题或任务。
识别、监控和修复意外行为或失败模式。
推动开发更精准的安全干预措施。
为了提高用户对模型的透明度和信任,需要实现以下几点: 首先,模型的开发和训练过程应该是开放和透明的,让用户可以了解模型的构建和训练的详细信息。包括模型的架构、训练数据、训练参数和评估指标等信息。 其次,模型的结果应该是可解释和可追溯的,让用户可以了解模型是如何根据输入数据进行预测和决策的。包括模型的预测结果、预测的可能性和对预测结果的解释等信息。 第三,模型的更新和维护应该是公开和可追溯的,让用户可以了解模型的哪些部分已经更新、哪些部分还需要更新,以及更新的原因和影响等信息。 最后,模型的使用和结果应该是可追溯和可验证的,让用户可以了解模型的使用情况和结果是否正确和可靠。包括模型的使用记录、结果的验证和反馈机制等信息。 通过实现这些点,可以提高用户对模型的透明度和信任,让用户更好地理解和使用模型,从而提高模型的可
Goodfire这次公开的成果是针对R1的SAE,他们极度期待看到社区如何基于这些成果进一步发展,推动新的技术创新,旨在更好地理解和对齐强大的AI系统。
随着推理模型的能力和应用不断增强,像这样的工具将对确保模型的可靠性、透明度,以及与人类意图的一致性起到关键的作用。
参考资料:
在推理模型的背后:如何让人工智能真正地「思考」?本文将探讨Reasoning Model的内部工作机制,并探索如何让人工智能真正地「思考」,从而更好地解决复杂的问题。
目前,人工智能(AI)技术的发展速度飞快,AI在各个领域的应用日益广泛,AI技术的潜力和前景仍然很广泛。
基于可解释性原则的R1模型解释平台,旨在为用户提供更加透明、可靠的模型解释结果。