腾讯自研AI大模型混元2.0发布:总参数406B,激活参数32B
IT之家12月5日消息,腾讯自研AI大模型混元2.0(Tencent HY 2.0)今日正式发布,包括Tencent HY 2.0 Think和Tencent HY 2.0 Instruct。
腾讯表示,HY 2.0 采用混合专家(MoE)架构,总参数达406亿字节,激活参数为32亿字节,支持256K上下文窗口,推理能力和效率“居国内顶尖行列”,在文本创作和复杂指令遵循等实用场景上展现出突出的表现。
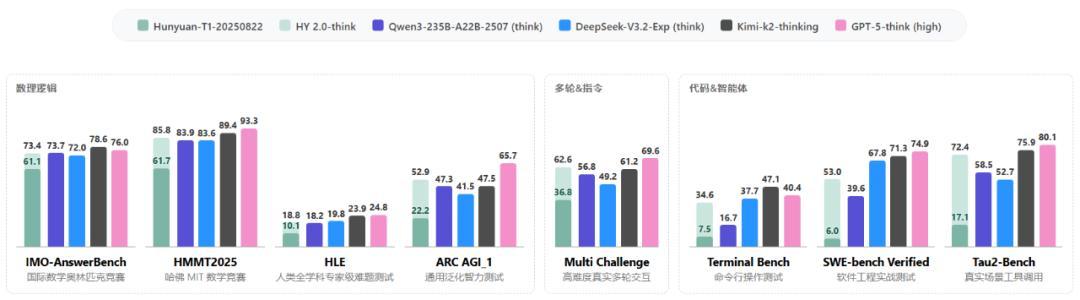
相比上一版本(Hunyuan-T1-20250822)模型,HY 2.0 Think 显著改进了预训练数据和强化学习策略,发挥出在数学、科学、代码、指令遵循等复杂推理场景中的综合优势,稳居国内第一梯队,泛化性大幅提升。
数学科学知识推理:腾讯混元通过高质量数据驱动的 Large Rollout 强化学习,极大地提高了 HY 2.0 Think 的推理能力。在国际数学奥林匹克竞赛(IMO-AnswerBench)和哈佛 MIT 数学竞赛(HMMT2025)等权威测试中,取得了优异的成绩。同时,结合预训练数据的进步,模型在 Humanity's Last Exam(HLE)和泛化性的 ARC AGI 等任务上也取得了明显的进步。
腾讯混元通过重要性采样修正缓解了训练和推理不一致问题,实现了长窗口RL的高效稳定训练。同时,腾讯混元通过多样化可验证的任务沙盒,以及基于打分准则的强化学习,显著提高了 HY 2.0 Think 在 Multi Challenge 等指令遵循和多轮任务的效果。
代码与智能体能力:腾讯混元构建了规模化的可验证环境和高质量合成数据,这极大地增强了模型在Agentic Coding和复杂工具调用场景下的落地能力,并在SWE-bench Verified和Tau2-Bench等面向真实应用场景的智能体任务上实现了明显的跃升。
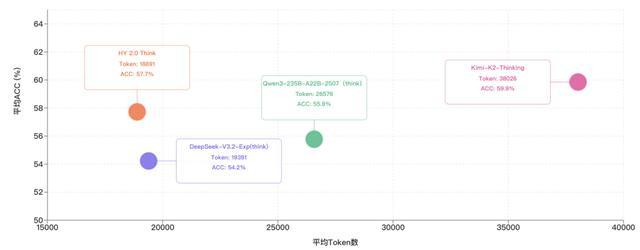
HY 2.0 Think 引入了精细的长度惩罚策略,巧妙地平衡了思维链的效率和效果,避免模型堆砌废话,以实现计算资源的更高效分配。通过对照 HY 2.0 Think 在 IMO-AnswerBench、HMMT2025、ARC-AGI 和 HLE 这四个权威推理任务上的表现,以及相应的 token 消耗,可以看到 HY 2.0 Think 在取得类似的准确率下,消耗的 tokens 数量更少,单位 token 的智能密度处于“业界领先水平”。
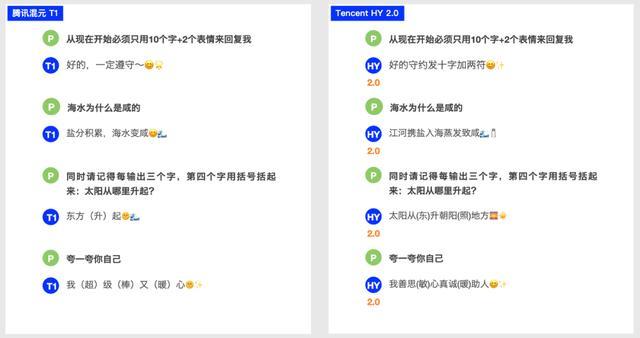
基于RLVR+RLHF双阶段的强化学习策略,HY 2.0的输出“质感”明显提升,在文本创作、前端开发、指令遵循等实用场景上展现出明显的差异化优势。
与上一个版本的模型相比,HY 2.0 在指令遵循方面的准确率获得了明显的提升。
IT之家从腾讯混元公告获悉,作为腾讯自研的通用大模型,HY 2.0 将继续推进其进化,未来将在代码、智能体、个性化风格和长程记忆等方面进行迭代,以全面提高模型在实际应用场景中的表现,而相关技术和模型也将通过开源形式向社区开放。
目前,HY 2.0 已经率先率先在元宝和ima等腾讯原生AI应用接入,并在腾讯云上线API,用户可直接体验或接入部署。
