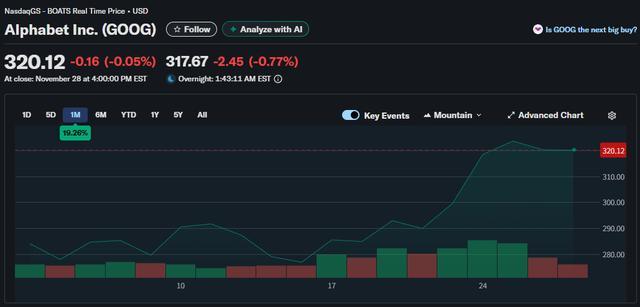
谷歌憋了十年的大招,让英伟达好日子到头了?
要说上个月谁是科技巨头里最大的赢家,世超提名谷歌应该无人有异议吧?
靠着性能炸裂的 Gemini 3,短短半个月,股价蹭蹭快速上涨,不仅如此,还在竞技场内展现出激烈的竞争力,拳击 OpenAI,竞技场外再次展现出脚踢英伟达的强大实力。
回撤一点,问题不大。
至于卖铲子的老黄如何也被卷进枪案中,原因非常明显,Google 表示,Gemini 3 Pro 是在自研的 TPU(Tensor Processing Unit)上进行训练的,至少从字面上看,是没有提到英伟达一个字儿。
紧跟着,媒体和吃瓜群众开始纷纷猜测,说什么谷歌这回,可能真的要终结 CUDA 的护城河了。
那么问题来了,看似让英伟达好日子到头的TPU,到底是个啥?
从名字上也能看出,它实际上是一类芯片,和 GPU 是近亲,只不过做成了 AIเฉพาะ版。
虽然 TPU 最近才引起大伙儿的注意,但实际上这是一个从 2015 年延续到现在的老项目。
第一代 TPU 长这样,长约73厘米、宽约10厘米、高约3厘米,外观简洁、无扩展卡设计,体积小巧却内置多个核心处理器,为 Google 的深度学习算法提供了强大的计算能力。

当时,谷歌正经历技术转型的阵痛,力图将传统的搜索推算算法完全替换为深度学习。然而,结果表明,这种 GPU 不仅不敷使用,还极其耗电,根本无法满足实际需求。
GPU 的问题,在于它太想全能了,试图承担太多的责任。为了什么都能干,不得不搞了一套复杂的架构,层层叠叠的硬盘、内存、显存、核心互相协作。
这带来一个大麻烦,在芯片的世界中,搬运数据的成本远远超过计算本身。数据从显存跑到核心,虽然物理距离可能只有几厘米,但电子却需要绕过复杂的路线,像翻山越岭般地穿越。
GPU(图形处理器)的工作方式是指其处理图形和计算任务的步骤和过程。以下是 GPU 的工作方式的一个概述: GPU 首先接收来自中央处理器(CPU)的指令,并将其转换为图形相关的指令。然后,它将这些指令发送到内存中,获取所需的图形数据。随后,GPU 对图形数据进行处理,包括像素的渲染、光照、阴影、反射等效果。最后,GPU 将处理后的图形数据发送回 CPU,用于显示在屏幕上。

于是,电费的大半并没有花在算数上,而是全然花在了送快递的路费上了。最后变成热量,还需要恳求风扇吹一吹。
在图形渲染时,缺乏毛病,因为画面高度随机,要获取素材的难度很高,只能回显当前存现取的结果。
然而 AI 矩阵运算,每个数的计算逻辑,如何计算,以及谁计算,计算的次数都是固定的。我清楚地了解这个数的计算结果,一会儿还将继续使用,GPU 硬盘需要将其存储下来,等待其他进程再次从计算单元中取回,这种操作不纯粹是一种浪费吗?
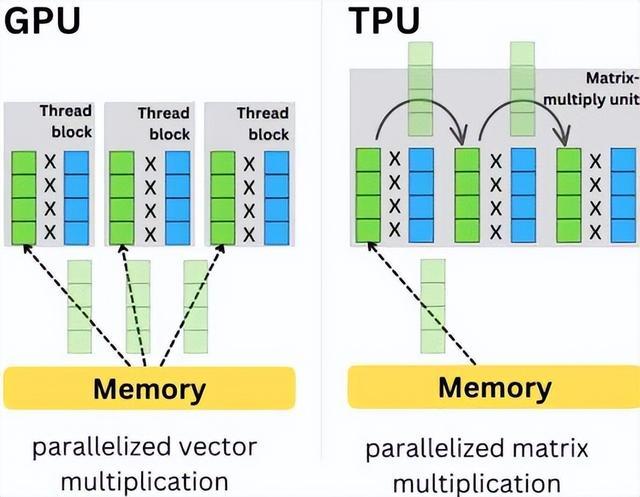
于是,作为一个 AI 专属工具人,TPU 就这样出生了。它将 GPU 那些用不上的图形、控制流、调度模块等等拆分、压缩。
核心思路是专门对人工智能(AI)最常用的矩阵乘法进行优化,创造了一种名为「脉动阵列」方法。
随着每个数据的计算一旦开始,它们将在密集排列的计算单元之间进行传递,而不允许它们在未完成计算前回存储在单元中,这样就可以减少频繁的读写操作。
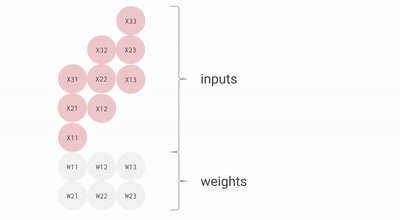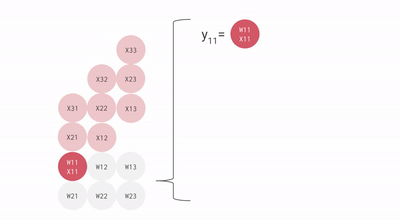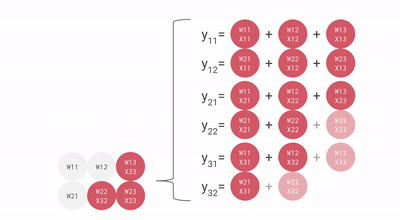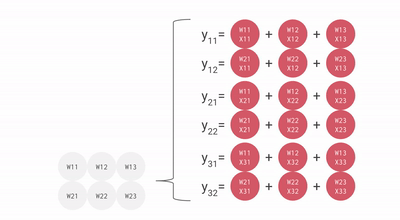
TPU 的每个周期计算操作次数达到了数十万级别,这是 GPU 的近十倍之多。初代 TPU v1 的能效比达到了同时期 NVIDIA Tesla K80 的 30 倍,展现出极高的性价比。
当然,最开始谷歌也是边缘试探,没玩那么大。TPU也仍然只是边缘探索,未发挥出太多的作用。它主要用于推理,而不是训练,功能单一,完全无法与GPU相媲美。
自第二代TPU问世以来,谷歌开始将其功能扩展到内存中,实现容量和数据传输速度的显著提升。这样,TPU便能够在计算的同时快速记录和修改海量的中间数据,如梯度和权重,从而点亮了训练的技能树。
随着 TPUv3 规模的不断增加,模型训练速度不断提升。
然而,数十年来,明明使用 TPU 训练推理的成本更低,性能也与 GPU 不相上下,为何巨头们仍然非得抢夺英伟达的芯片呢?
事实上,人们并不是不渴望拥有TPU,而是谷歌的控制权太强,一直在施加强制性措施。所有的TPU都被租赁而不是出售,紧密绑定在谷歌云计算平台上。大公司无法将TPU带回家,实际上是将其生命线交给了谷歌云,心中总是感到毛骨悚然。生怕英伟达的脆弱命运在谷歌的控制下直接走向了断绝。
即使这样,苹果也未能抗拒便宜的大碗诱惑,终于租了些许。
而这回热度这么高,一方面是 Gemini 3 证明了 TPU 的成功,品质可靠;另一方面,是因为第七代 TPU Ironwood,谷歌终于舍得亮相。

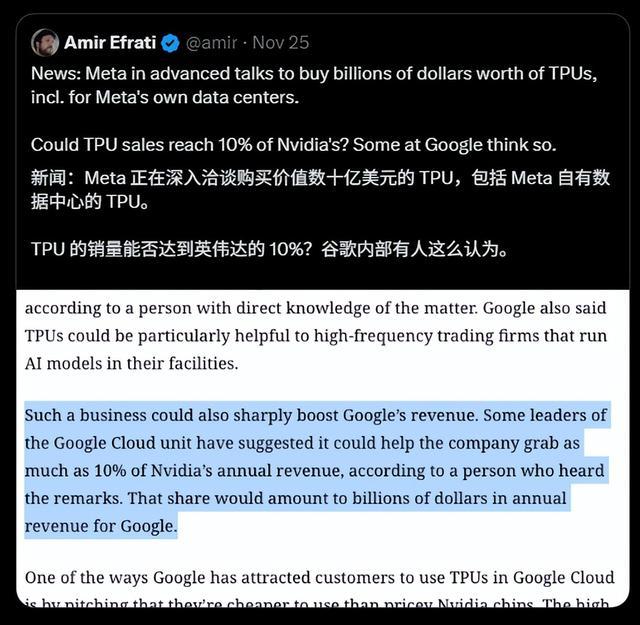
根据The Information的报道,Meta已经与谷歌展开了数十亿美元的大合同洽谈,计划从2027年开始在机房部署TPU,并计划在明年最早租用谷歌的TPU。
消息一出,谷歌股价即刻上涨 2.1%,而英伟达股价则下跌 1.8%。
甚至有谷歌内部人士放话,我们这一波大开张,可能会抢走英伟达几十亿美元的大蛋糕,直接切掉他们10%的年收入哦。
华尔街对 TPU同样情有独钟,认为这项技术具有无限的商业前景。连负责设计制造TPU的博通公司也因此而受益,业绩预期因此而被上调。
然而,要说 TPU 会取代 GPU,真不至于。
TPU是一种ASIC(Application-Specific Integrated Circuit),也称为专用集成电路。换言之,TPU除了擅长于AI领域的矩阵计算外,其他方面的性能并不出色。
这是它的优点,也是它的挑战和痛点。
TPU(Tensor Processing Unit)是一种专门为机器学习和人工智能 optimize 的处理器,旨在加速深度学习算法的计算和推理速度。TPU 的工作方式是通过将机器学习模型中的矩阵乘法和加法操作转换为低级的指令,这样可以充分利用硬件的并行计算能力和矢量处理能力。

赶上大模型当道的好时候,对矩阵计算的需求大得离谱,TPU跟着一步登天。但要是以后有啥更火的AI技术路线,不搞现在这一套,TPU分分钟失业。
然而,TPU因為太專精,一旦在計算上沒有性能優勢,就徹底失去價值。四年前的TPU v4,咱們已經很難見到它了。
相比之下,GPU则具有不同的特点。以五年前诞生在大模型浪潮前的3090为例,它之所以能够长久地保持其主力地位,是因为其24G超大显存和对CUDA的不抛弃不放弃的向下兼容生态,直到现在仍然是普通人玩AI的超值选择卡,能够轻松地跑起Llama 8B小模型。
退一步讲,就算 AI 这碗饭不香了,大不了回去接着伺候游戏玩家和设计师,照样活得滋润。

CUDA生态依然是英伟达最大的杀招。
这就好比你用惯了 iOS,虽然安卓也很好,但让你把存了十年的照片、习惯的操作手势、买的一堆 App 全都迁移过去,你大概率还是会选择下次使用 iOS。
现在的 AI 开发者也是一样的,他们的代码基于 CUDA 编写,调用的是英伟达优化的库,即使错误发生,修改方式也主要集中在 CUDA 上。
考虑转投 TPU?行啊,先将代码重构一遍,然后调整以适应新的开发环境。
即使强兼了 PyTorch,许多底层的优化和自定义算子仍然需要在 TPU 上重新调试。专门为 TPU 设计的 JAX 语言也提高了人才招聘的门槛。
对于大多数只想赶紧把模型跑起来的中小厂来说,与其费劲巴拉地去适配TPU,甚至根本搞不到,直接买英伟达芯片反而是最省事的选择。
谷歌自己仍然在大量采购英伟达的 GPU,即使自己不需要使用,这也是因为谷歌云拥有庞大的客户群体,需要大量的 GPU 来满足业务需求。
TPU 这波开卖,确实在大模型训练的这一块上,用经济划算的方式让英伟达付出了一个教训。但是,也绝对没有被夸大的,要抢占 GPU 的饭碗那么神气。
未来的算力市场,更加可能会看到 TPU 占据头部大厂的专用需求,而 GPU 继续统治通用市场。
然而,只要巨头们竞争起来,就有可能把算力价格打下来,这样看来,也是一件好事。