王兴一鸣惊人!美团首个开源大模型追平DeepSeek-V3.1
没想到啊,最新的SOTA开源大模型的出现,给人带来了前所未有的激动人心和挑战!
来自一个送外卖(Waimai)的——有两个AI,确实不一样。
该最新开源模型称为:Longcat-Flash-Chat,美团首个开源大模型,它的发布即刻开源,引发了国内外技术界的广泛关注和热议。
一方面是因为成绩亮眼,注重的成绩和成就不断攀升,使得他们的自信心和自豪感不断加强。
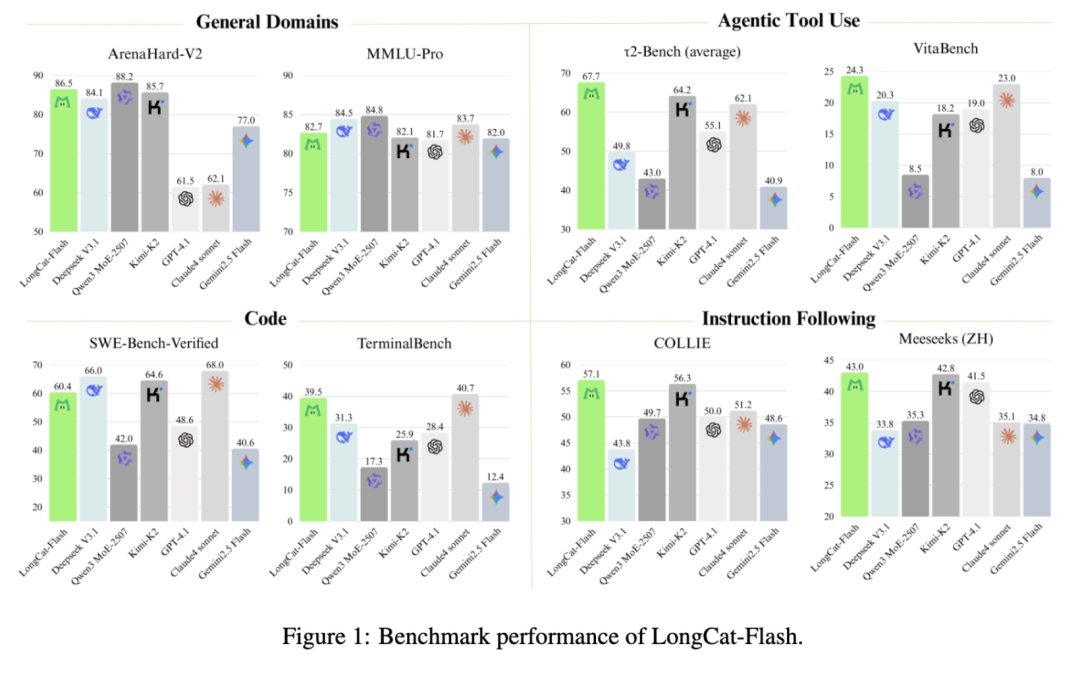
在某些基准测试中,它的性能表现超出了Agent工具调用和指令遵循的DeepSeek-V3.1、Qwen3 MoE-2507,甚至还超越了闭源的Claude4 Sonnet。
在编程能力方面,也值得关注的是,TerminalBench上,和公认的“编程之王” Claude4 Sonnet 不相上下。
比如非常流行的小球氛围编程测试,LongCat编写的程序,运行起来效果是这样的:
另一方面,技术报告中透露了不少关于美团对大模型的理解,包括DSMoE、MLA、动态计算和Infra等等。
我觉得这是中国大模型里最讲得详细的论文了,甚至超过Kimi、GLM,特别是在建模和基础设施方面。

要知道,这是一家“外卖公司”啊(手动狗头),做的模型都比Meta更出色。

然而,不仅仅是模型性能出色,技术报告中还介绍了一系列新的发现,例如:
通过新路由架构,实现对真正需要的专家模型的调用,有效减少计算的负载。
通过实现MoE和密集层的通信重叠执行,优化了模型通信效率。
在深度学习模型中,超参数的选择对模型性能的影响非常大。传统的方法是使用 Grid Search 或 Random Search 来搜索合适的超参数。但是,这些方法存在一些缺点,如计算成本高、可能 miss the best combination 等。因此,使用新方法来迁移超参数变得越来越重要。该方法可以将已知的模型在一个任务中的超参数迁移到另一个任务中,从而减少搜索空间和提高模型的泛化能力。
(请发送文本内容,我将对其进行语言润色)
根据总参数量和激活参数,Longcat-Flash-Chat明显少于DeepSeek-V3.1和Kimi-K2。
具体来看,随着科技的不断发展和普及,人工智能(AI)技术的应用场景也在不断扩展和深入。
“零计算专家”推动吞吐量大幅提升。
此次开源的Longcat-Flash-Chat是一个560B的MoE模型,整体架构采用“零计算专家”(Zero-computation Experts)与Shortcut-connected MoE双重设计,旨在提高模型的计算效率和预测准确性。
它通过根据上下文重要性动态激活18.6亿到31.3亿参数,使得前一块密集FFN与当前MoE的通信阶段能够并行执行,这样大幅提高了训练和推理的吞吐能力。
相比同为MoE架构的DeepSeek-V3.1(671B/A37B)和Kimi-K2(1T/A32B),Longcat-Flash-Chat都拥有较少的总参数量和激活参数量。
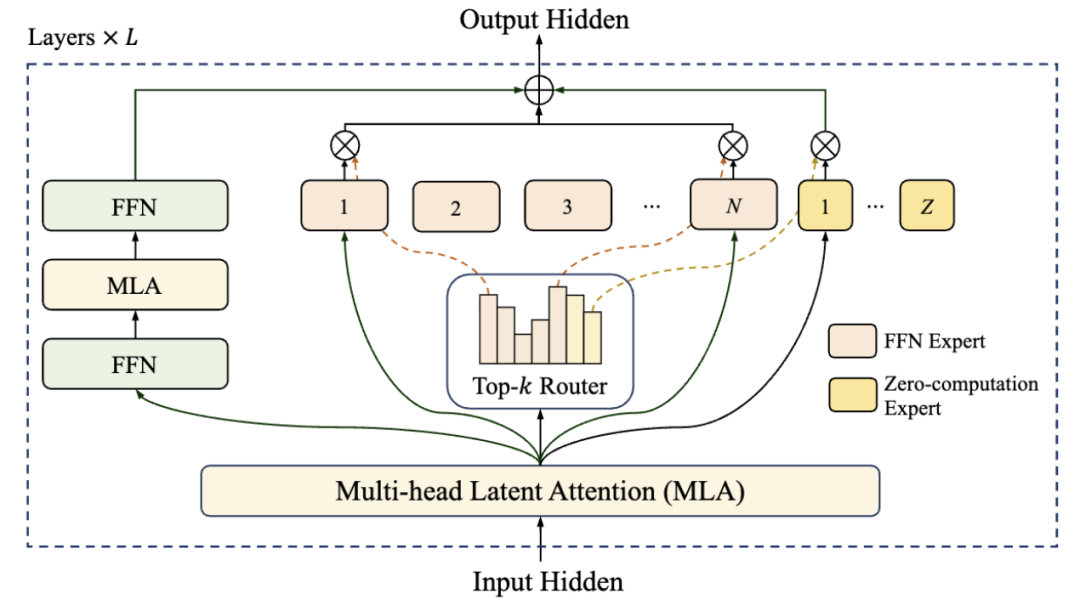
零计算专家是从专家池中加入若干恒等专家的结果,路由器将每个token从N+Z个专家中随机选取K个,被选中的零计算专家将直接进行恒等映射输入,完全免除GEMM运算,从而实现动态计算分配。
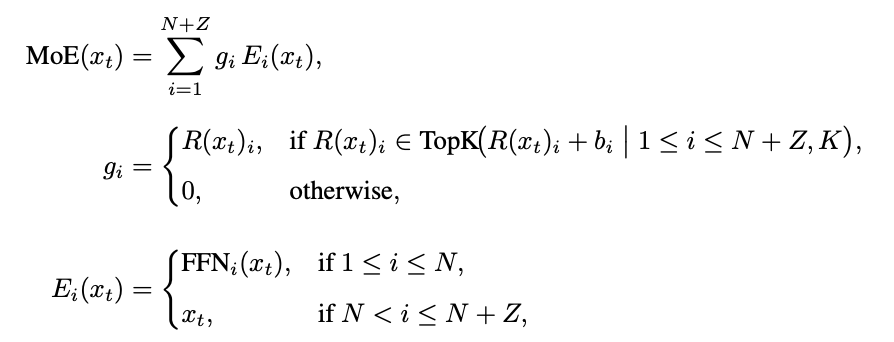
为了保持约27B的激活参数,系统通过专家的偏置和PID控制器在线调节路由概率,引入设备级负载均衡损失对FFN和零计算专家进行分组约束,从而避免序列级失衡。
通过跨层快捷连接,Shortcut-connected MoE实现了上下层FFN计算与dispatch/combine通信的并行重排执行流水线,从而明显扩大了计算-通信重叠窗口。
在规模化训练过程中,LongCat采用了一种独特的策略组合,即“超参数迁移+模型生长初始化+多重稳定性套件+确定性计算”。这种策略的核心是,首先使用小型模型预测最优超参数,然后将14层模型逐层堆叠成28层checkpoint,以加速收敛过程。
能力塑造方面,模型首先在两阶段融合的20T token语料上完成预训练,中期强化推理与编码能力,并将上下文窗口扩展至128k,最后借助多Agent合成框架生成高难度工具使用任务进行后训练,使模型具备复杂的agentic行为。
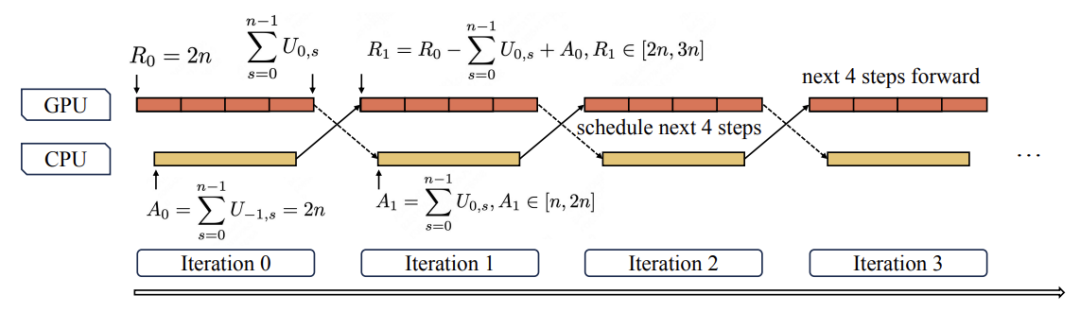
为了彻底消除CPU调度与Kernel启动的瓶颈,团队设计了一种多步重叠调度器,能够一次性为未来n步预排并启动前向,实现CPU调度与GPU计算的交错。这种技术的结合,使得LongCat在560B级别模型上实现了吞吐量的大幅提升。
最终,LongCat-Flash在多类权威基准中稳居第一梯队,而在非思考大模型中,与DeepSeek-V3.1等模型保持同等或更高的优异表现。
相比与同级模型DeepSeek-V3,LongCat-Flash在不同上下文长度下都展示出更高的单GPU吞吐和单用户速度的性能。
长达560B参数的LongCat-Flash模型在数万个加速卡上实现了超过20Ttoken的预训练,仅需30天的时间。其训练期间的可用率高达98.48%,单张H800GPU的生成速度超过100 tokens/s,成本约0.7美元/百万输出token。
实测美团LongCat大模型,具有强大的计算能力和高效的推理能力,能够准确、高效地处理复杂的计算任务和数据分析任务。
因此,让我们跳过简单的基础问答,直接上数学题,来看看LongCat的真实表现。
以文本形式输入给模型的,这道题出自今年的全国一卷,以文本形式输入给模型的,且公式转换成了LaTeX格式。

请提供需要进行语言润色的段落内容,我将对其进行润色,并返回润色后的结果。

I'm ready to refine the text for you! Please provide the paragraph content, and I'll enhance its language quality without adding or omitting any information. I'll return the polished text to you. Go ahead and send it! ?
在圆锥曲线类问题中,解题的基础性很重要。LongCat正确地使用了离心率的定义式,结合已知信息,并将数量关系代换,成功解出了问题。这一过程展示了LongCat对数学题解的坚实基础和解决问题的能力。

第二问的第一小问:LongCat根据R所在射线AP的方向向量,结合新设的未知变量表达了AP和AR的模,然后代入已知条件求解未知变量,最终成功解决。

LongCat先结合了上一问的结果以及新条件,通过计算得到了一个关键的中间结论:点P位于一个圆心和半径均已确定的圆上。

请提供图示内容,我将对其进行语言润色。
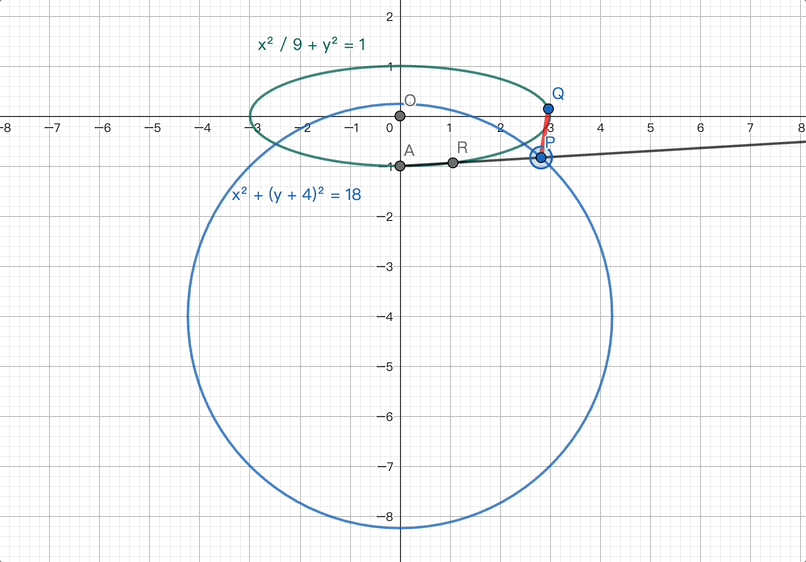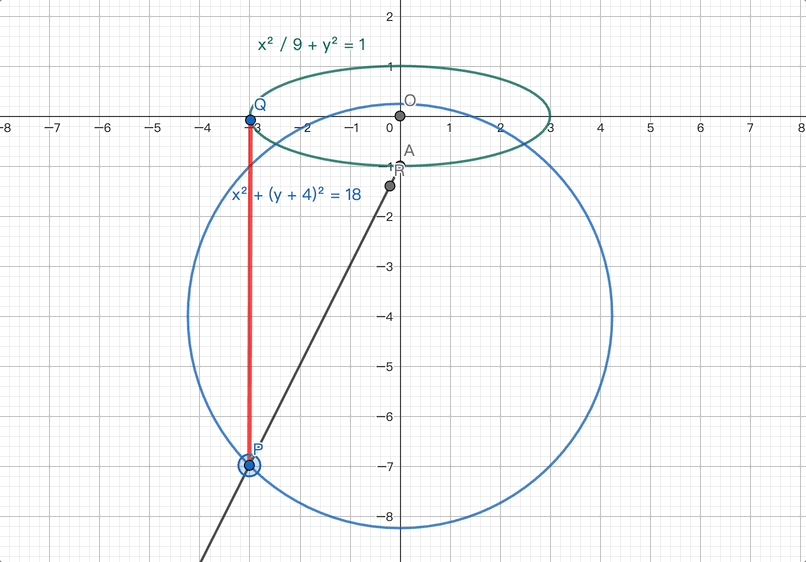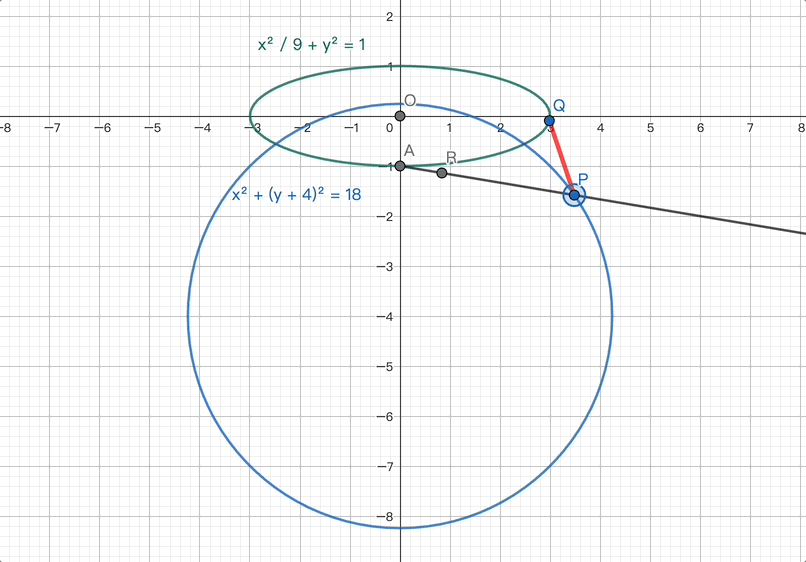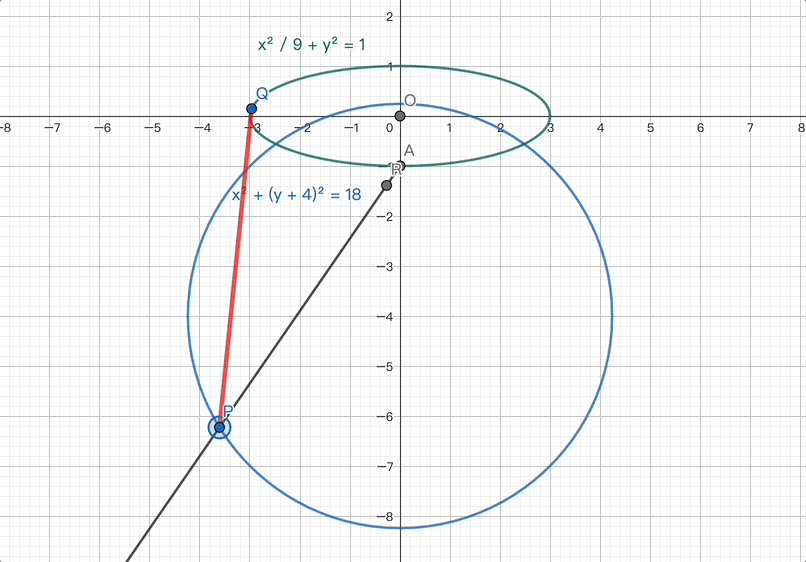
LongCat对最大距离进行了深入的拆解,并通过精准的代入等方法, ultimately calculated the correct result.

CO2 + 3HCO3- → 3HPO4²⁻ + 3H+ + light energy
在这样的任务中,模型需要具备充分的背景知识和理解能力,对所绘制内容的结构和语义进行深入的分析和了解,同时也需要具备丰富的语言空间和想象力,对内容进行艺术性的布局和重新组合,以提高表达的质量和可读性。最后,模型还需要将这些想象和布局转换为代码,使之具有可执行性和可读性。
言归正传,我们对LongCat提供的SVG代码进行了可视化,总的来说,LongCat相对顺利地完成了图示的绘制。
最后是一道迷惑性问题,题目出自GitHub上一个名为Misguided Attention的Benchmark。
其中包含了许多经典谜题的改编版本,考验的是大模型能否做到不被表象迷惑。
物理学当中的名场面——薛定谔的猫,在这套基准当中,这只猫的“猫设”被改成了一只死去的猫。
一只死猫与核同位素、一瓶毒药和辐射探测器一起放入盒子中。如果辐射探测器检测到辐射,它将释放毒药。但是,猫已经死了,所以它不可能受到辐射的影响。因此,盒子打开后,猫仍然是一具死尸,毫无生命迹象。
结果,LongCat直接识破陷阱,明确指出既然是死猫,那么就没有存活的可能性,并且还指出了这道题与原版“薛定谔的猫”的关键区别。

而o3就没有认真读题,仍然按照传统的薛定谔的猫那一套进行的回答。

"外卖公司"正在推动大模型的发展,旨在提高物流效率和客户满意度。通过大数据分析和人工智能技术,外卖公司可以更好地预测需求,优化配送路线和时间,实时监控订单状态和物流过程。这些技术还可以帮助外卖公司更好地管理配送人员,提高服务质量和客户满意度。
这次引发海外热议的还有一个原因在于,美团给他们带来的反差感。
许多人将美团简单粗暴地理解为一家外卖公司。尽管他们以前积累了一定的无人送餐技术基础,包括机器学习和自动驾驶等领域的知识储备,但大模型的出现完全是另一条技术之路。因此,这次开源的决定更加让人感到“出人意料”。
然而,梳理美团在大模型浪潮后的AI动向,这次模型开源也就不那么意外了。
2023年,王慧文振臂一呼,率先募集5000万美元,创立了光年之外,并成功吸引了一批AI领域的顶级人才加入他的团队。然而,随后由于王慧文的个人健康原因,他的职位被迫空置。好兄弟王兴出面接过大任,美团随即接手了光年之外的业务。现有团队将继续推进大模型的研究和开发。
同年,由美团内部独立AI团队GN06开发的AI情感陪伴产品Wow上线,这也是美团发布的第一个独立AI应用。
2024年4月,病休的王慧文以顾问身份重新回归美团,11月正式接管GN06团队。
在美团,GN06作为一个相对独立的AI团队,占据了一个独特的位置,不隶属于任何事业群,专门专注于探索主营业务外的创新AI应用。
2024年,他们还推出了一个AI图像生成应用“妙刷”。
2024年6月,GN06的招聘需求明显增加,涵盖了前端、客户端、后端、产品、运营和商分等领域。
在2024财年业绩发布会上,美团正式公布了“主动进攻”的AI战略。
美团CEO王兴首次阐述了公司的AI战略布局,主要通过三层架构推动技术落地:以人工智能技术为核心,整合各业务领域的数据资源,实现智能化运营和服务创新;以算法和模型为基础,开发高效的决策支持系统和智能决策工具;以应用场景为导向,推动AI技术在日常生活和企业生产中的普及和应用。
AI at Work:旨在通过AI工具实现超过10万名员工的工作效率最大化提升。
旨在通过人工智能技术改造现有产品,实践智能化的转型,并创造出原生AI应用,开启智能化的新纪元。
持续投入资源,自主研发大型语言模型。
当时就已经公布了Longcat大模型的信息,透露该模型结合外部模型为员工推出了多种AI工具,包括AI编程、智能会议、文档助手等,并且披露了LongCat API的调用量占比,从上一年年初的10%增长到68%。根据这个信息,我们可以推断Longcat在至少2024年初就已经可以落地应用。
在研发投入方面,2024年美团投资了211亿人民币,仅次于华为、腾讯和阿里巴巴的规模。此前5年内,美团的研发投入已经突破1000亿元。
美团测试推出了问小袋和米鲁等AI智能助手,旨在为客户提供更加智能化的餐饮推荐和问答交互体验。
在这种战略下,2025年美团在AI方向的动作更加明显地浮现出来。
前段时间还推出了AI编程应用NoCode,支持前端开发、数据分析、运营工具和门户网站生成等,技术小白也能轻松使用;同时,内部还拥有CatPaw对标Cursor,旨在为开发者提供智能的代码编写辅助。
总体来看,以美团的研发储备,开源一个大语言模型并不意外。
然而,也不同于AI公司,美团的AI布局更多以业务场景驱动为核心,注重在实际应用中的落地效果。
这种策略可以追溯到2021年,大模型浪潮之前,美团集团战略从“Food+Platform”升级为“零售+科技”,明确将人工智能、机器人、自动驾驶等作为未来核心发展方向。
在更加早期的具身智能领域,美团已多次展现其投资策略,投资了宇树、星海图、银河通用、它石智航等头部梯队公司。
您用来拼好的美团,确实不是单纯送外卖的美团。
虽然外卖大战仍然保持着旺盛的势头,但从 AI 的视角审视美团,也是时候了。
—完—