OpenAI发最强图像生成模型API!可高级定制功能,价格低至0.15元/图

编译金碧辉,呈现出绚丽的光芒,照亮着整个画面。
编辑:程茜
智东西4月24日报道,今天凌晨,OpenAI发布了图像生成模型GPT-Image-1,目前已经对所有开发者开放API。该模型不仅能够生成高质量的图像,还可以完成一些更加复杂的定制功能,例如可以通过设置参数来控制审核敏感度,同时还可以控制图像的质量、生成速度、背景和输出格式等。
与ChatGPT之前的图像生成功能相比,gpt-image-1不仅允许开发者精心控制生成图像的敏感度、生成效率、背景、输出格式、渲染质量和压缩质量,还在多个技术方面进行了升级。其中,对敏感度进行了分级控制,使得生成图像的灵活性和可靠性得到了进一步的提高。此外,单张图像生成的耗时从ChatGPT时期的平均3.2秒缩短至0.8秒,完成了生成效率的优化。该技术还扩展了输出格式,支持静态图、动态图、MP4、PSD等多种格式的输出,并将分辨率细化为三档,进行渲染质量的分级控制。最后,开发了平衡算法,实现了智能降噪的功能。
此外,新模型还具备了更加强大的图像合成能力,可以一次性生成多张图像,并使用这些图像作为提示词来实现合成,达到类似Photoshop的蒙版功能,并且可以更改图片的透明度等效果,这些功能都是之前版本所不具备的。
目前,GPT-Image-1已经通过API向全球开发者开放使用。在价格方面,该API的使用费用为文本输入每100万token 5美元(约36.05元人民币),图像输入每100万token 10美元(约72.1元人民币),图像输出每100万token 40美元(约288.39元人民币)。根据实际使用情况的估算,生成低质量1024×1024图像的成本约为每张0.02美元(约0.15元人民币),中等质量图像约为每张0.07美元(约0.50元人民币),高质量图像约为每张0.19美元(约1.37元人民币)。 Adobe、Figma等众多知名企业已经将该模型集成到其产品中。
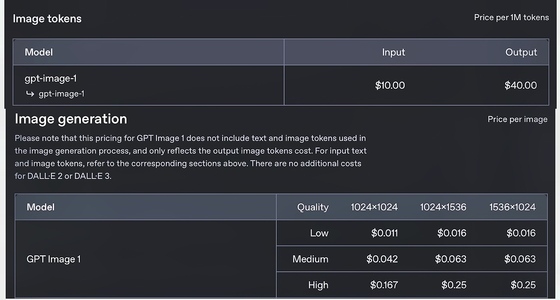
以下是润色后的内容: gpt-image-1模型的API价格,以便您更好地了解其成本效益,官方提供了明确的定价信息,包括每个请求的价格、每月的配额和超出配额的价格等等。
OpenAI联合创始人兼CEO萨姆·阿尔特曼(Sam Altman)在社交平台X上发表了一则早晨简报,高度赞扬该模型的最新成就,并透露gpt-image-1模型与ChatGPT版本之间存在着明显的差异,特别是图像生成速度、背景和格式等方面。
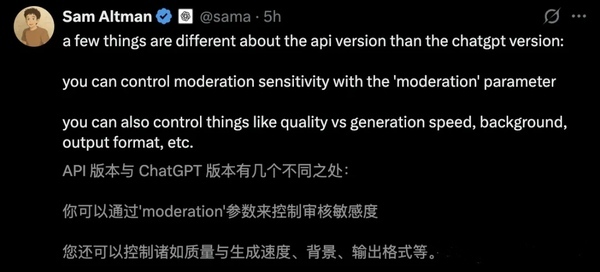
▲图为萨姆·阿尔特曼今日早晨在社交平台X上的发言。
一、三大核心亮点:多图生成、图像编辑、图像变体
根据OpenAI介绍,GPT-Image-1是OpenAI目前最新且最先进的图像生成模型。
该模型的第一个亮点是可以通过设置n参数来进行图像生成端点,并根据文本提示创建图像。

▲图为 GPT-Image-1 模型生成图像的具体参数。
输入具体参数就可以生成一张图像质量高、高保真的图像。同时,GPT-Image-1 能够涵盖丰富多样的视觉风格,满足不同的创作需求。
第二个亮点是,可以充分发挥用户已上传的一个或多个参考图像,创造出全新的图像。

▲图为GPT-Image-1模型使用四个输入图像来生成包含参考图像中物品的礼品篮的全新图像。
第三个亮点是,通过精确的图像编辑功能,可以对用户上传的图像和蒙版进行高精度的“修复”(inpainting)操作。该操作将蒙版透明区域替换为合适的图像,黑色区域保持不变,同时要求蒙版和要编辑的图像格式和大小相同,蒙版图像还需要包含alpha通道。

▲图为GPT-Image-1模型通过图像编辑功能进行“修复”后的新图像。
此外,根据OpenAI的透露,API返回的图像数据是以base64编码的png格式,但用户也可以选择生成jpeg或webp格式图像。需要注意的是,在使用jpeg或webp格式时,用户还可以指定output compression参数,以控制压缩级别,范围为0-100%。例如,输入“output compression=50”的指令,以便gpt-image-1模型将图像压缩到50%。
还需要注意的包括,方形图片以标准质量生成的速度最快,默认大小是1024×1024。
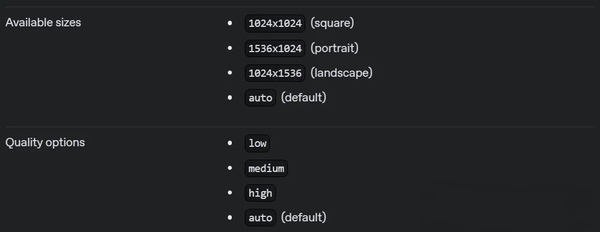
▲图为自定义输出的具体细节。
二、支持高级功能定制,能够精细化控制生成效果。
基于 GPT-Image-1,开发者可以通过指定质量、大小、格式、压缩和是否需要透明背景等参数来自定义输出。例如,默认情况下 API 将返回单个图像,但开发者可以通过设置“n”参数来在单个请求中一次生成多个图像。
目前,图像生成功能仅可通过Image API 使用,OpenAI 官方表示正积极努力将支持扩展到 Responses API。
在价格方面,该模型通过生成专门的图像token来生成图像,延迟和最终成本直接与渲染图像所需的token数量成正比。较大的图像尺寸和较高的清晰度设置将导致更多的token被消耗,自然也会产生较高的成本。
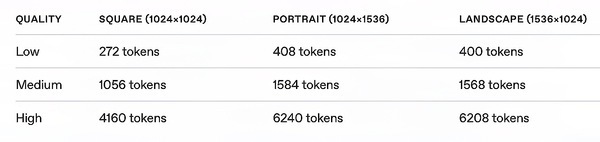
▲图为 GPT-Image-1 模型根据不同消耗的token数量可能产生不同的费用。
Image API提供了三个独特的端点,分别具有不同的功能。首个端点“Generations”能够根据文本提示从头开始生成图像,第二个端点“Edits”可以使用新的提示部分或完全修改现有图像,第三个端点“Variations”则用于生成现有图像的变体。
gpt-image-1擁有高品質的圖像生成能力和在圖像創作中運用世界知識的能力。根據OpenAI介紹,使用者也可以將專門的圖像生成模型DALL·E 2和DALL·E 3與圖像API結合使用。
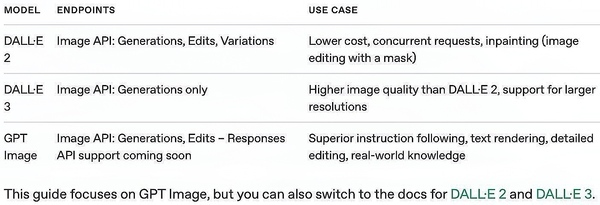
▲图为GPT-Image-1模型、DALL·E 2和DALL·E 3的端点和用例。
三、复杂需求处理时间长,多轮生成难以保证一致性。
尽管 GPT-Image-1 模型功能强大且用途广泛,但是仍存在一些限制。
在内容审核方面,所有的提示和生成的图像将根据OpenAI官网的内容发布政策进行严格的过滤和审核。在使用gpt-image-1进行图像生成时,开发者可以通过"moderation"参数来控制审核的严格程度,该参数支持"auto"(默认,标准过滤,限制创建某些可能不适合年龄的内容类别)和"low"(限制较少的过滤)两个值,以确保生成的内容符合相关法规和社会规范。
gpt-image-1在其他方面也存在一些限制。例如,该模型在处理复杂的提示可能需要长达2分钟的时间,存在消息延迟现象;相比于DALL·E系列,gpt-image-1在文本渲染方面有了明显的改进,但在精确的文本放置和清晰度方面仍然存在一些问题;在一致性方面,虽然gpt-image-1能够生成一致的图像,但是在多轮生成中,对于重复出现的角色或品牌元素,可能偶尔难以保持视觉一致性;在构图控制方面,尽管gpt-image-1在遵循指令方面有所改进,但在结构化或对布局敏感的构图中,精确放置元素可能仍然存在一些困难。
结语:OpenAI的新模型API,解锁图像创作更多的可能性。
OpenAI推出的GPT-Image-1模型为开发者带来了强大的图像生成工具,它们丰富的功能和特性有望在图像创作、设计等多个领域得到广泛应用。
尽管存在一些限制,但随着技术的不断发展和优化,未来其图像生成能力可能会进一步加强和完善,为用户带来更多的惊喜和可能性。